《独孤九剑》-随机应变
某云厂商维保项目案例分享
内部资料严禁外传
特别说明:
面对甲方群里一些低级错误的看法和发言注意的事项:术业有专攻,私下委婉指正。初级技术好脸面、喜欢更正、不注意方式方法。以后如果你们做项目经理,更多的不是解决技术问题,而是解决人的问题。
对于固态硬盘和机械硬盘,之前更换时某云厂商会审核5000小时的通电时间。根据后续沟通,现在已经都没有了5000小时要求了,但是对更换硬盘的“预故障”检测跟严格了。此信息跟大家同步一下,如果有维修群中,对更换件通电时间超过5000小时有疑问,可以再群里 @某同事乙 和我,我们再继续沟通。
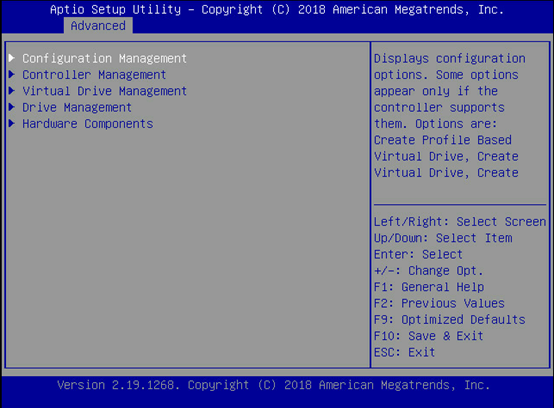
目前工作特别要注意的事项:
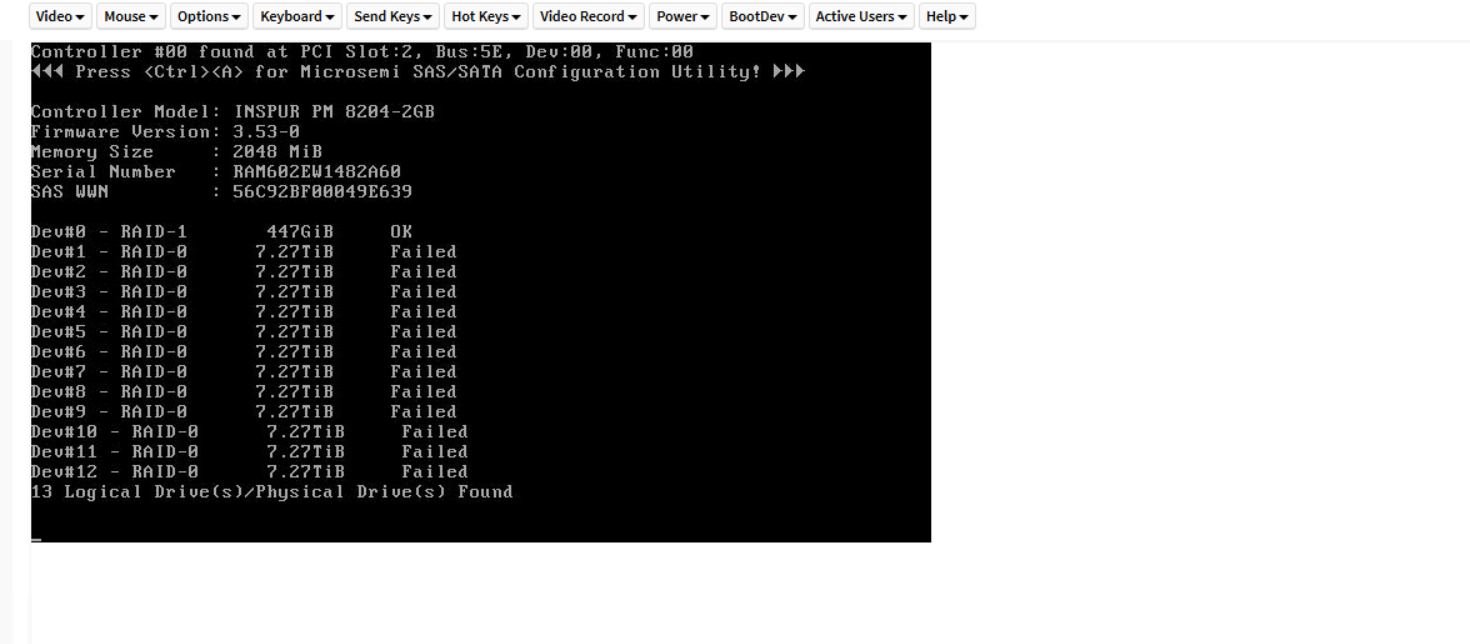
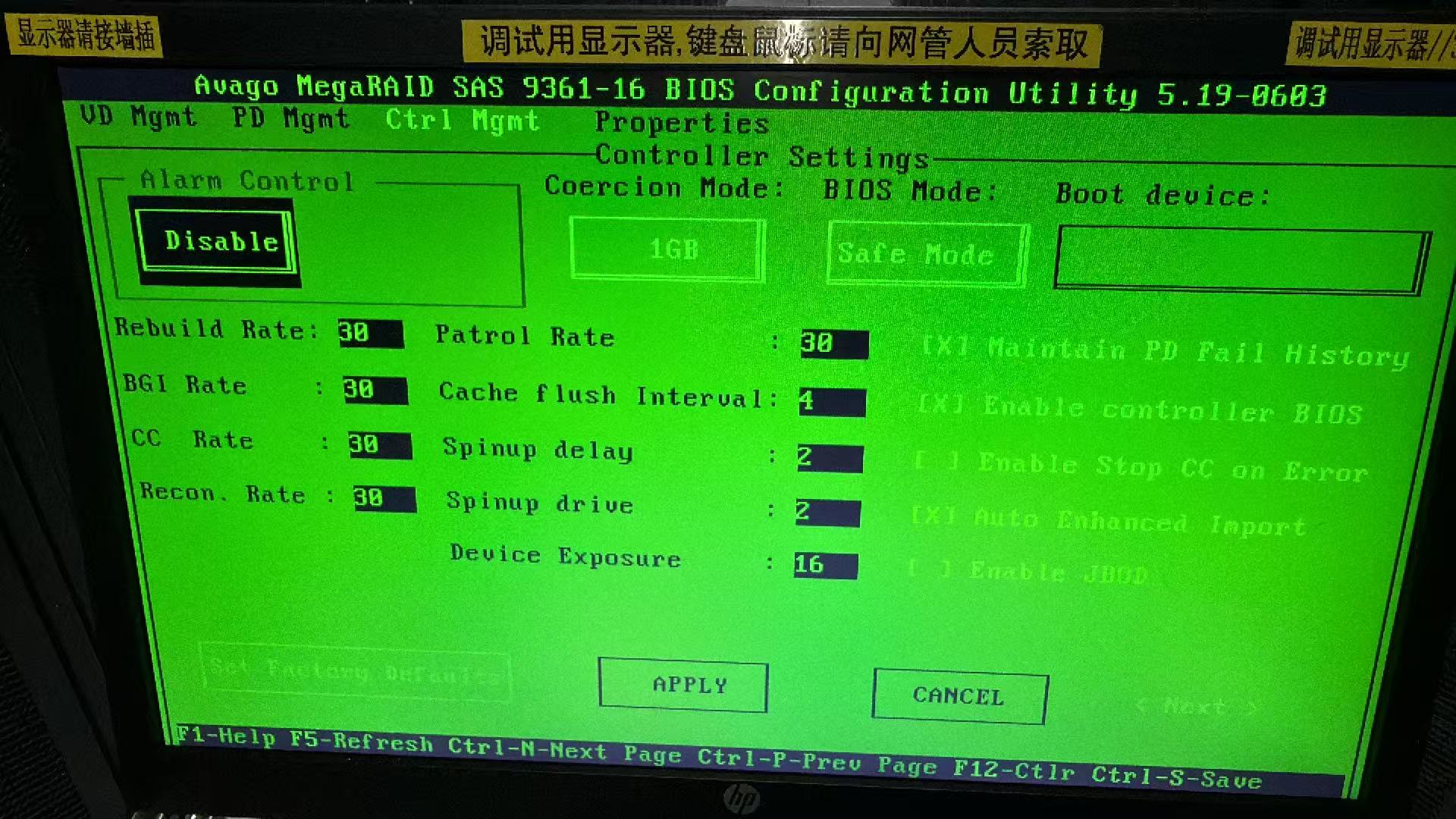
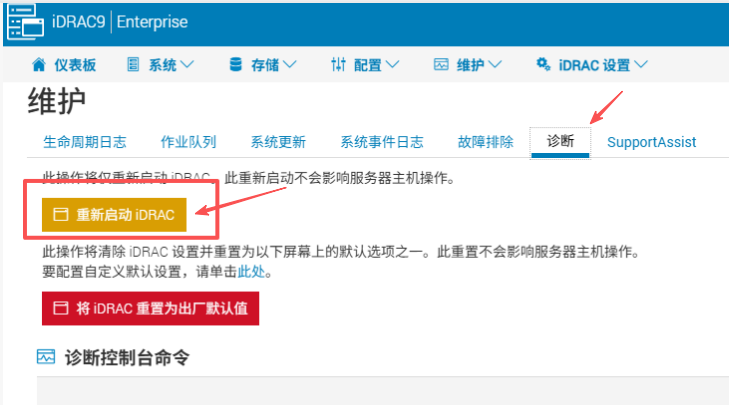
超聚变带外不通,关机断电后服务器不通电(小问题变大问题);
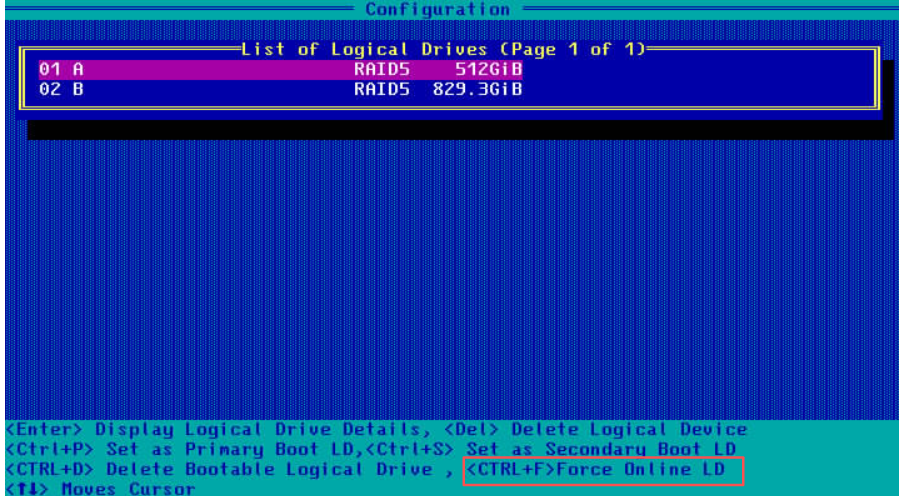
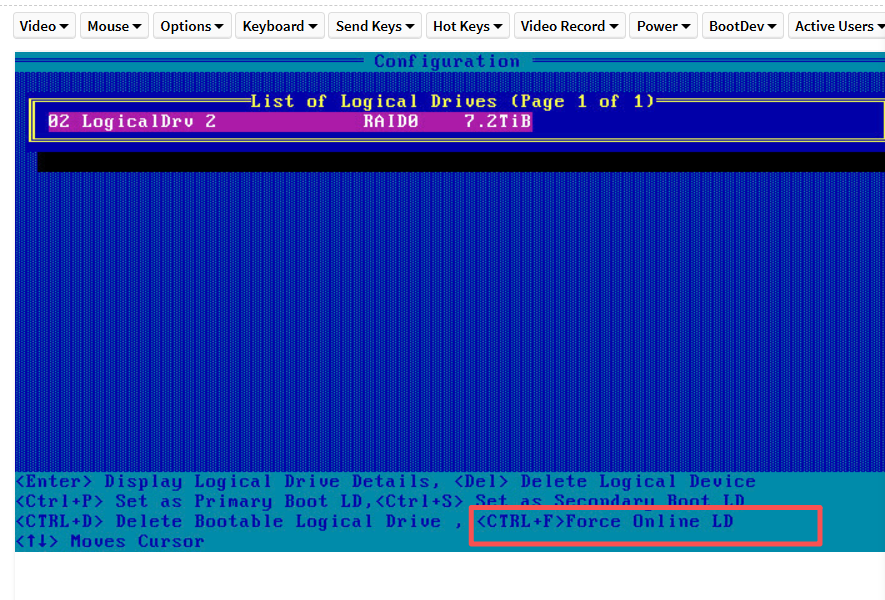
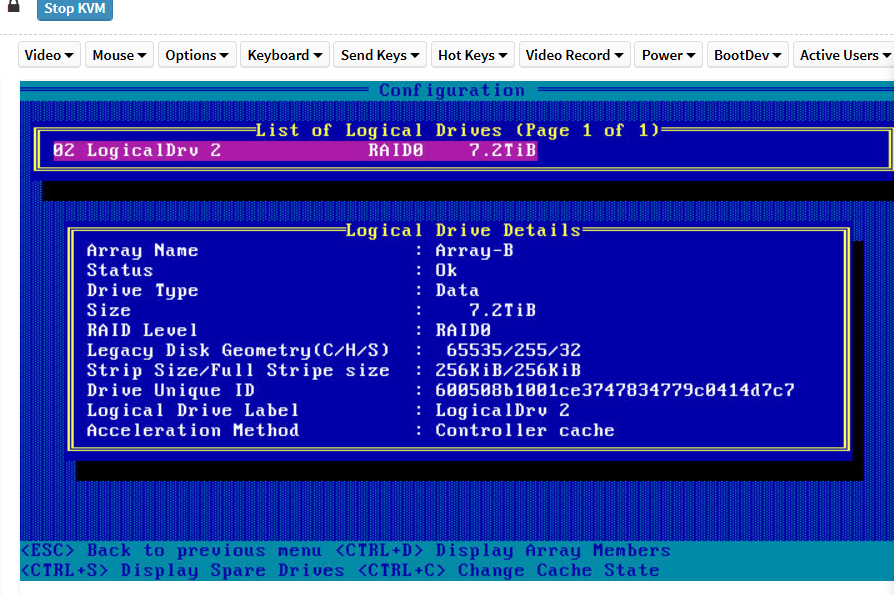
单盘raid 0更换未注释,开机进入恢复模式:
发邮件——》收件人后续可能会转发其领导,进行服务升级——》统一某同事丙发送;
更换主板后刷SN
超聚变——》确定工具和方法
HP——》确定方法
DELL——》确定方法
H3C——》新华三在Bios中直接改——》但 R4900 G3最麻烦——》确定工具和方法
浪潮——》确定工具和方法
曙光——》有两个工具和方法
某内部维修群这个群解散了,端口确认直接联系:某同事甲,硬件维修和采集信息可以联系我协调处理 1XX-XXXX-XXXX (微信同号)
维修外事项加分,可以抵扣工单超时,但不划算,尽量工单不超时。
增加二线工程师,工单转发和支持分组
转发工单——》每周轮换,主动的发邮件——》各省混在一起,分省容易漏单——》A班:周一、周三、周五,B班:周二、周四、周六、周日——》22:00分以后第二天再转发邮件和微信(一级二级单除外)
对一线支持——》被动的接请求——》分省支持——》某同事乙:浙江、江西,湖北,某同事丙:上海、福建、河南,优先支持特定省的一线——》特定二线忙,可以找另外一个二线支持
案例分享的时候,不会提到人名和省份名字,工程师也不要多心,没有指责、批评的意思。“不是暗指你个人”,是为了提高大家的技术水平,这点强调一下。就像咱们第一次开会时说的:工程师业务上的错,不完全是一个人的错。根据这件事的改进,一定是我们团队的整体的提升。
邮件信息里的设备型号可能不准,例如:设备型号RH5288 V3实际是RH5288 V5,购买主板的时候要根据设备序列号去确认一下,最好以PN码购买备件。
在时效范围内:优先处理集团单(以工单表格为准,报修邮件无法区分),四级故障4天,三级故障3天,二级故障1天,一级故障(5分钟,2小时,4小时)
服务梯次要求和二线支持:
第一次报修:时间优先尽快处理;
第二次报修:安抚客户,提高优先级,尽量早到,明确具体的故障原因。可以跟二线交流确认思路;
第三次报修:必须通知二线支持人员(第一次不知道;第二次不小心;第三次故意);
必须通知二线人员的情况:
单个维修单处理时间超过2小时;
同故障第三次维修;
用户提出特别高的要求。
业务接口人对咱们非常重要,要注意维护客户界面,对他们提出的要求不要简单、直接的拒绝,委婉拒绝(站在他的角度和利益考量表述拒绝他),如果拒绝他的要求的事项影响到维修件事case完成一定要谨慎,实在拿不准一定要通知我。另外各种操作要跟接口人说一下:换部件、关机、PE重启等涉及完成事件case的所有操作。
尤其是离开维修现场,一定要跟业务接口人沟通确认。总体上业务接口人都非常理解工程师,但现有2次沟通出现意外情况都是没有跟业务接口人明确沟通离场产生的。
有的时候一个单子有业务接口人,还有另外一个报障人,报障人更了解故障。一些具体的故障细节,如果从业务接口人获取不到的话,可以跟报障人确定,最好加微信,报障人很多时候有夜班。
在维修过程中,使用服务器带外账号密码,一定要避免泄露带外账号密码给其他人(无论是甲方其他人员,或者还是第三方人员)。
现在集团工单,也可以正常提交挂起,挂起时间不允许超过7天,工单总时长不允许超过10天。
咱们进群,最好把备注改一下,改成:中亦安图-自己的名字,尤其是和要跟贺冰杰团队交流的群。
你们的辛苦我都知道,有些工程师入行没有多久。有经验的工程师,处理时间过长、或第二次维修(含)通知我一下,第二次我不打扰你的思路,只提供建议,不影响积极性。第三次就要按照我的思路来。
分享我们工作在IT运维中的位置,希望大家相互支持、相互帮助,逐步提高自己认知和能力
关于节假日、重要会议期间的重保工作注意事项:
针对“9月5日凌晨江西省审批3台维修单实际维修4台”事件进行深刻反省和事件回溯,对全员进行风险教育;
强调“重保”活动实际是对业务接口人维修权限的收回,由COC统一进行管理,所有维修工单都要经过COC审批通过才能进行。“重保”对维修审批的目的是为了防止因为一下小的操作造成不可预知的重大影响,如果出现这种情况不是影响一个人,会影响多个关联岗位和关联环节,一定要充分重视;
入室岗位的审批过程,实际上是一个确认风险的过程,也是一个备案的过程。对于实际设备与入室信息的机柜不同不能进行维修,尤其是网络设备;
对于重点事项,在周例会中进行强调,并增加类似的考试环节(会议中未提及此项,计划进行问答考试和对电话无法接通情况进行考核);
预计9月8日会有大量工单的新增保修,同时要尽快进行存量工单的处理,备件要核实确认,可以多申请一些备件。
各位跟客户约挂起,一定要是表达是客户某云厂商的原因,不是我们的原因,不能以“备件没到”之类的原因向用户说要去挂起。一般客户不会问挂起的原因,因为老客户已经约定俗成了。如果新用户问,可以说:按照维修的计划,先处理昨天的工单,如果您比较着急的话,我给您在当天的工单顺序调早一点……。
如果用户问起备件什么时间到货的情况,给自己打个提前量:如果预估上午能到,就说下午。今天下午能到就说第二天。这里面有:我们给用户的信息,用户感觉是一种承诺,如果早到了用户有一种惊喜的感觉。
江西案例:修错主机,对流程更改:每个主机的在维修先,先把设备序列号拍照给业务接口或配合人员,经过确认后再进行维修(这个动作是为了保护工程师自己)。如果现场配合人员临时增加维修主机,需要尽量谨慎,优先委婉拒绝,如果一定要进行“没有工单的维修”必须要求提出需求的人员通过微信发送文字描述给现场工程师,现场工程师通知二线后再进行。此事件的教训:对服务器要有敬畏之心,服务器中实际的业务我们并不清楚,相当于是一个“黑盒”,我们本以为只中断了10分钟,后来用户说过了1天才完全恢复。
针对于如上情况的改进:对维修的主机在操作前不只进行“文字描述”确认,需要“拍照”给对接人活对接群。拍照内容:“设备的SN和资产标签”。此项工作是为了保护工程师自己。
上海案例:清除阵列卡缓存,实际操作为清除阵列卡配置。此事件的教训:对阵列卡操作,以及所有可能影响用户数据的操作务必小心谨慎。磁盘阵列恢复后,系统盘正常,数据库进行了Raid重建。用户电话第一次交流结果数据可以不要,只是备库的历史库。第二次交流:数据其他地方没有备份,仅此一份。着重提醒:硬盘有价,数据无价!
针对如上问题的改进:对阵列卡进行的操作未必尽失,同步业务接口人数据丢失风险,并适当夸大风险。
Linux系统恢复盘的制作和简单应用:更改密码和设备SN
(systemrescue的系统恢复盘无密码startx进入桌面,Slitaz_Linux的用户名和密码都是root)
下载三个文件:
解压两个压缩包会合并为一个文件:systemrescue-13.00-amd64 .iso
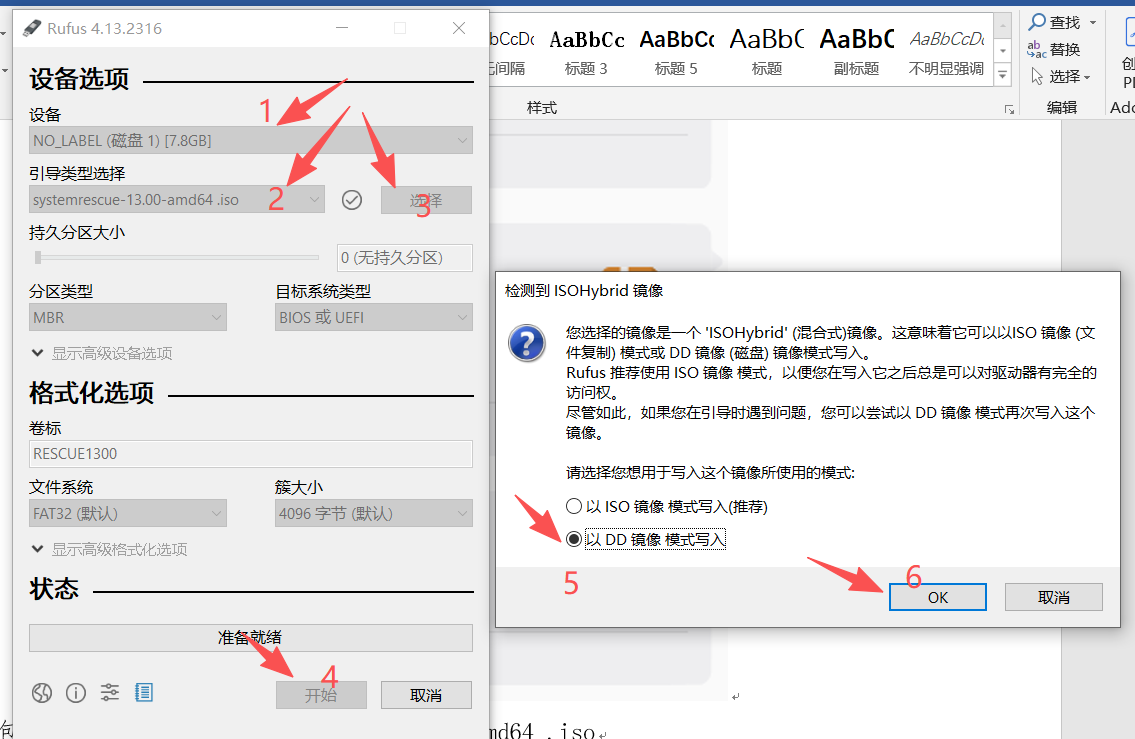
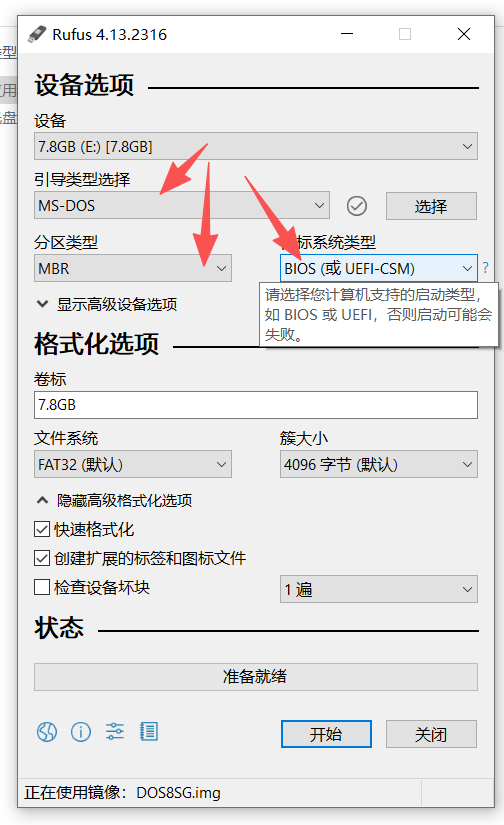
插上无数据U盘,使用rufus-4.13.exe工具写盘(直接镜像引导杏雨梨云无法完全加载,可以试一下Ventoy)
具体如下图,直至完成:
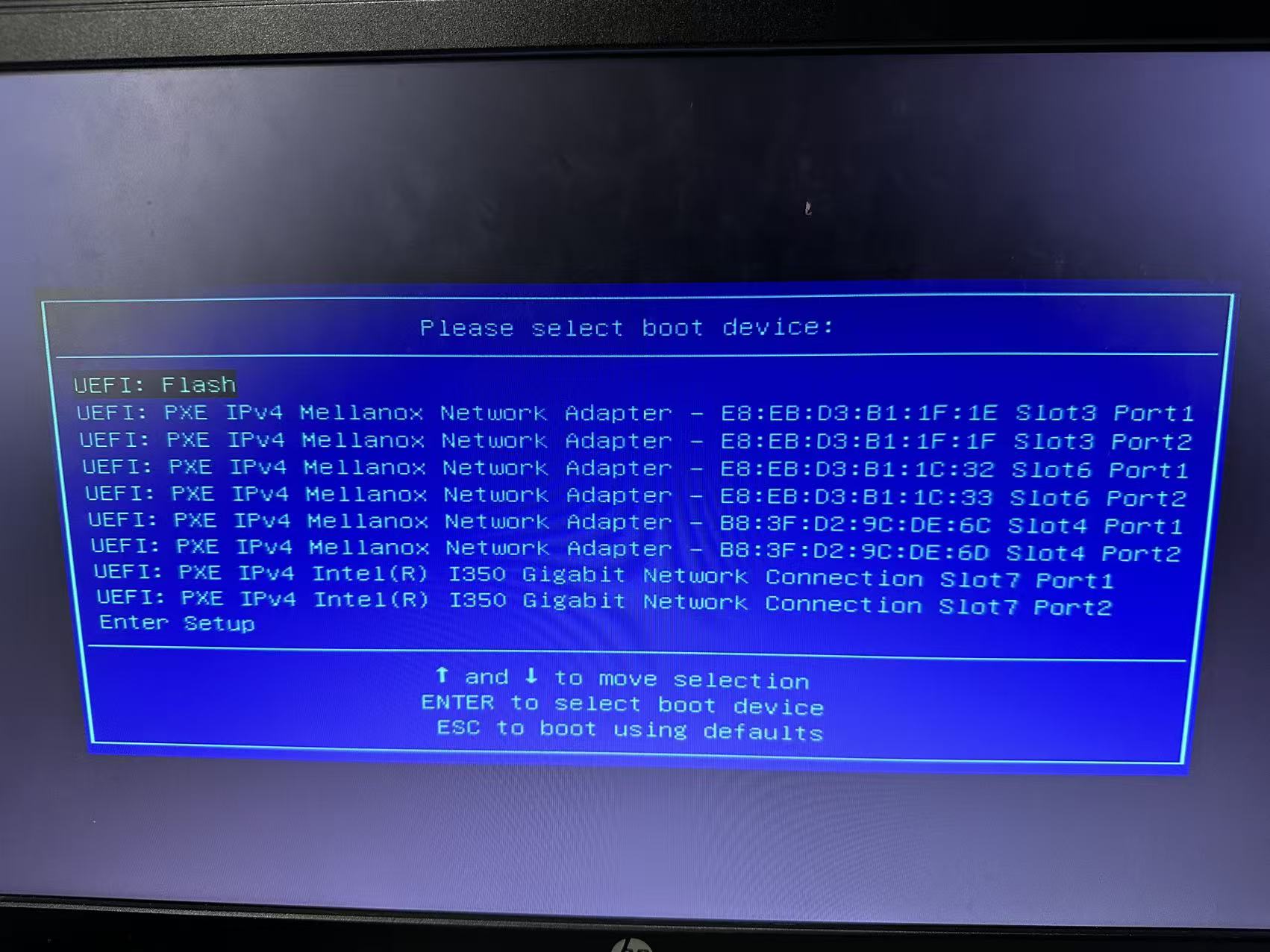
将制作好的U盘插到服务器上,通过Boot menu选择U盘引导。如果出现如下界面需要无法识别U盘需要更改启动模式为兼容模式Legacy/Compatibility。以下图为需要更改的情况:
更改完成以后,出现引导界面,选择第一项:
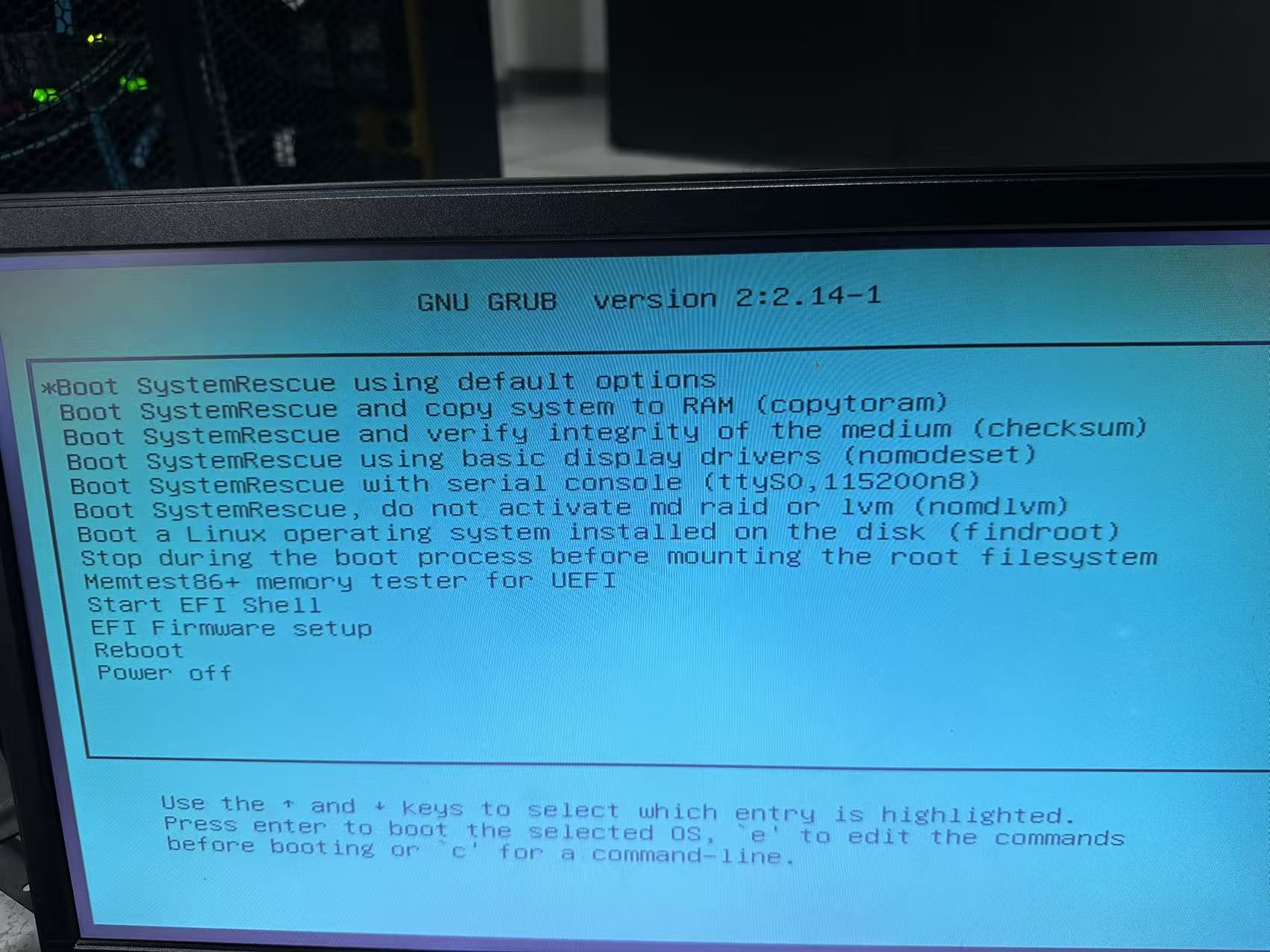
直到出现登录界面
切换目录
cd /usr/bin/
任务一更改带外用户密码步骤1:ipmitool user list 1
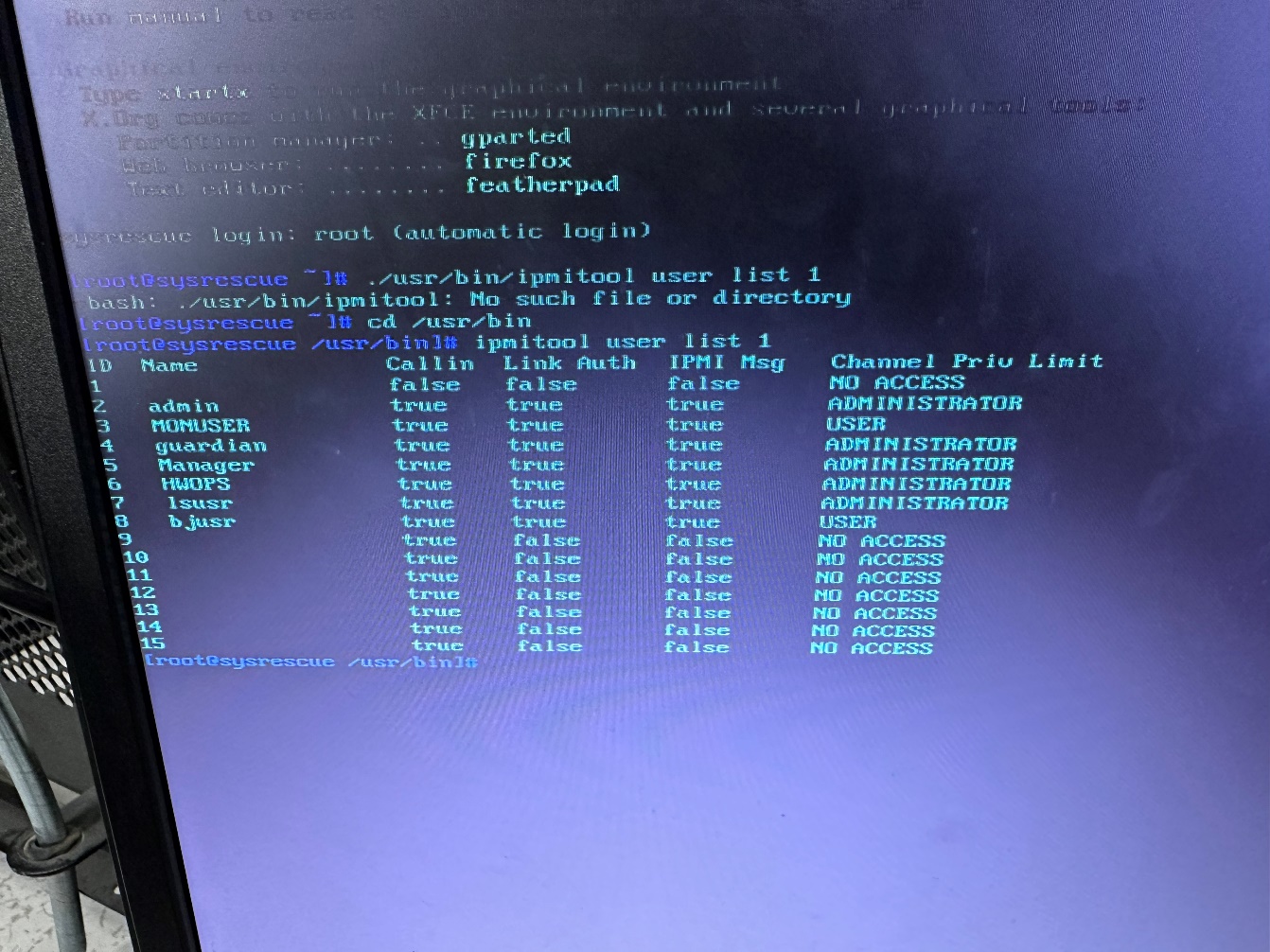
任务一更改带外用户密码步骤2:ipmitool user set password 2 default_pwd
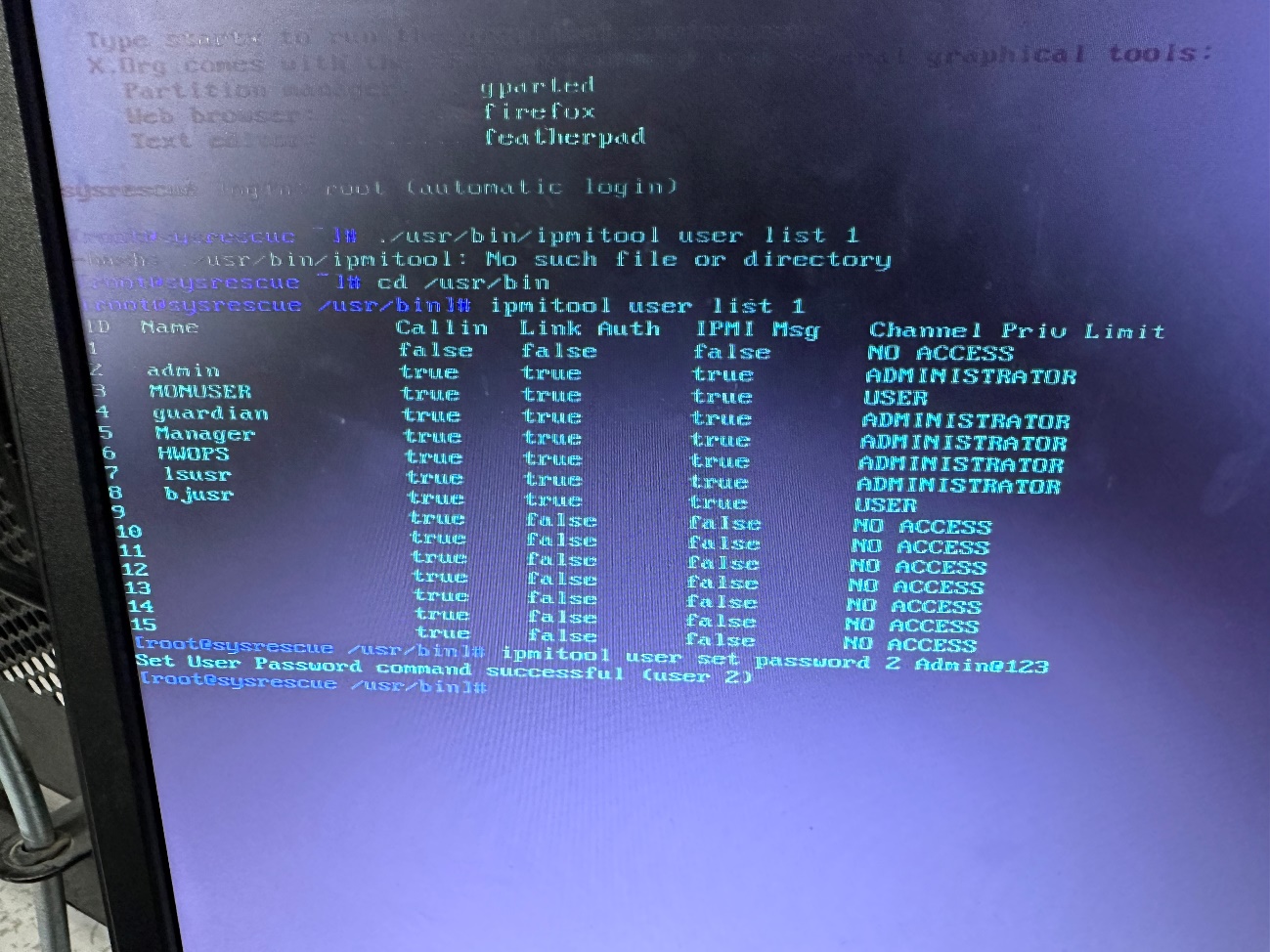
任务一更改带外用户密码步骤3:完成更改后,通过admin,修改后的密码:default_pwd登录。如果部分用户无法删除,需要切换用户或把无法删除的用户Admin改名为Administrator。或者将2好用户名字由admin改名为Administrator执行改名命令:ipmitool user set name 2 Administrator。
任务二更改主板SN步骤1:ipmitool fru print 0
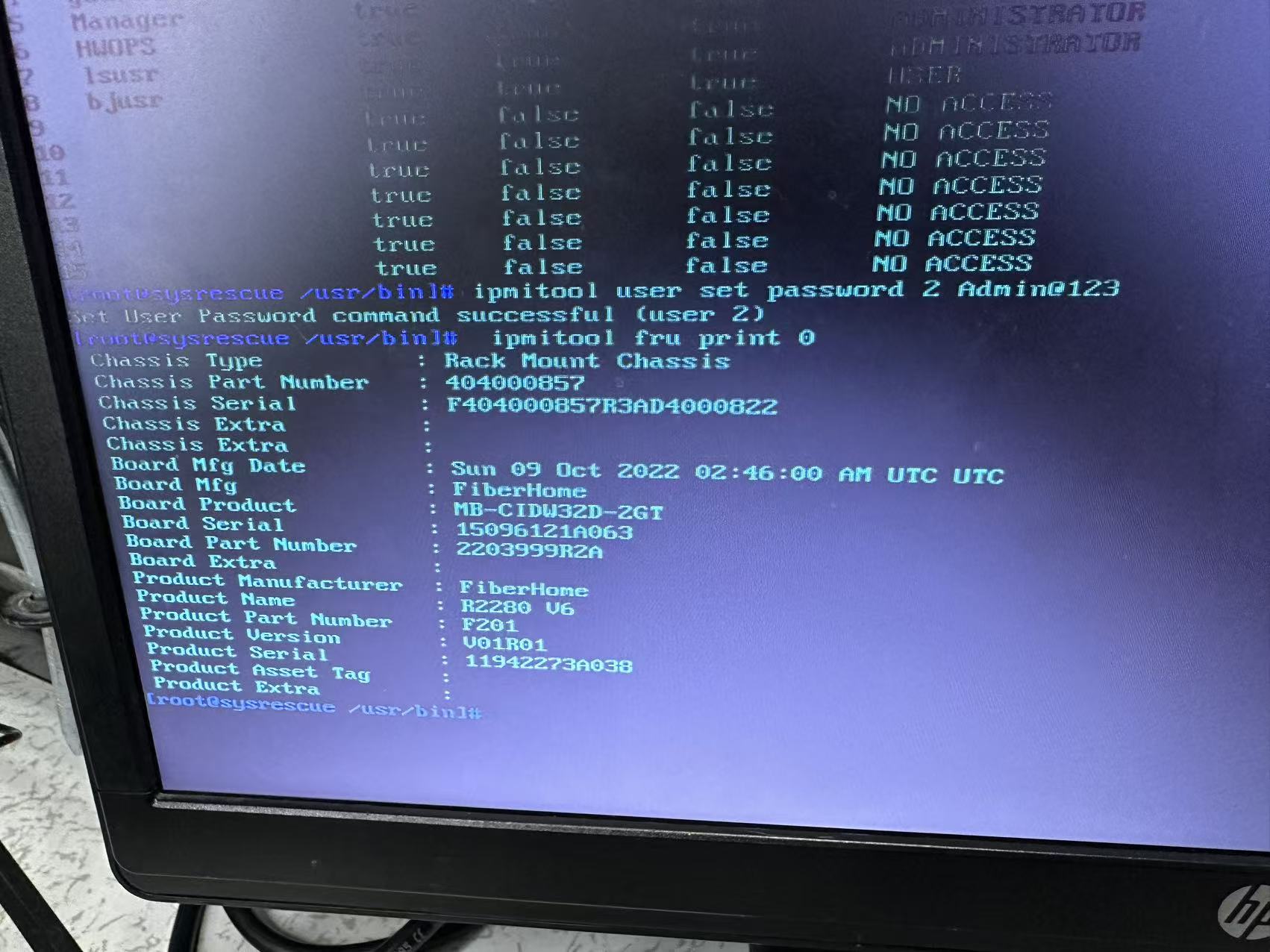
任务二更改主板SN步骤2:ipmitool fru edit 0 field p 4 “11936865A003”
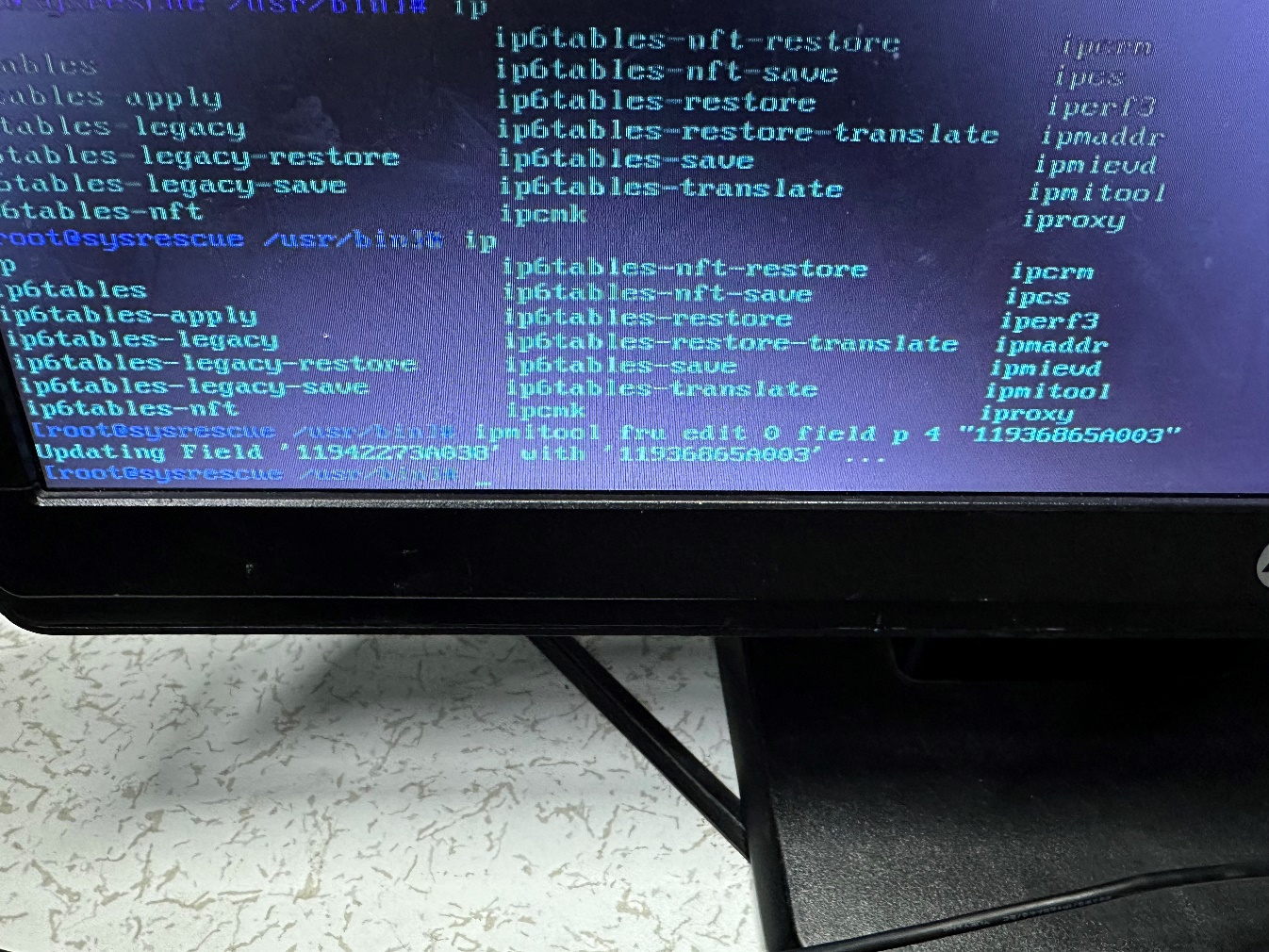
任务二更改主板SN步骤3:ipmitool fru print 0
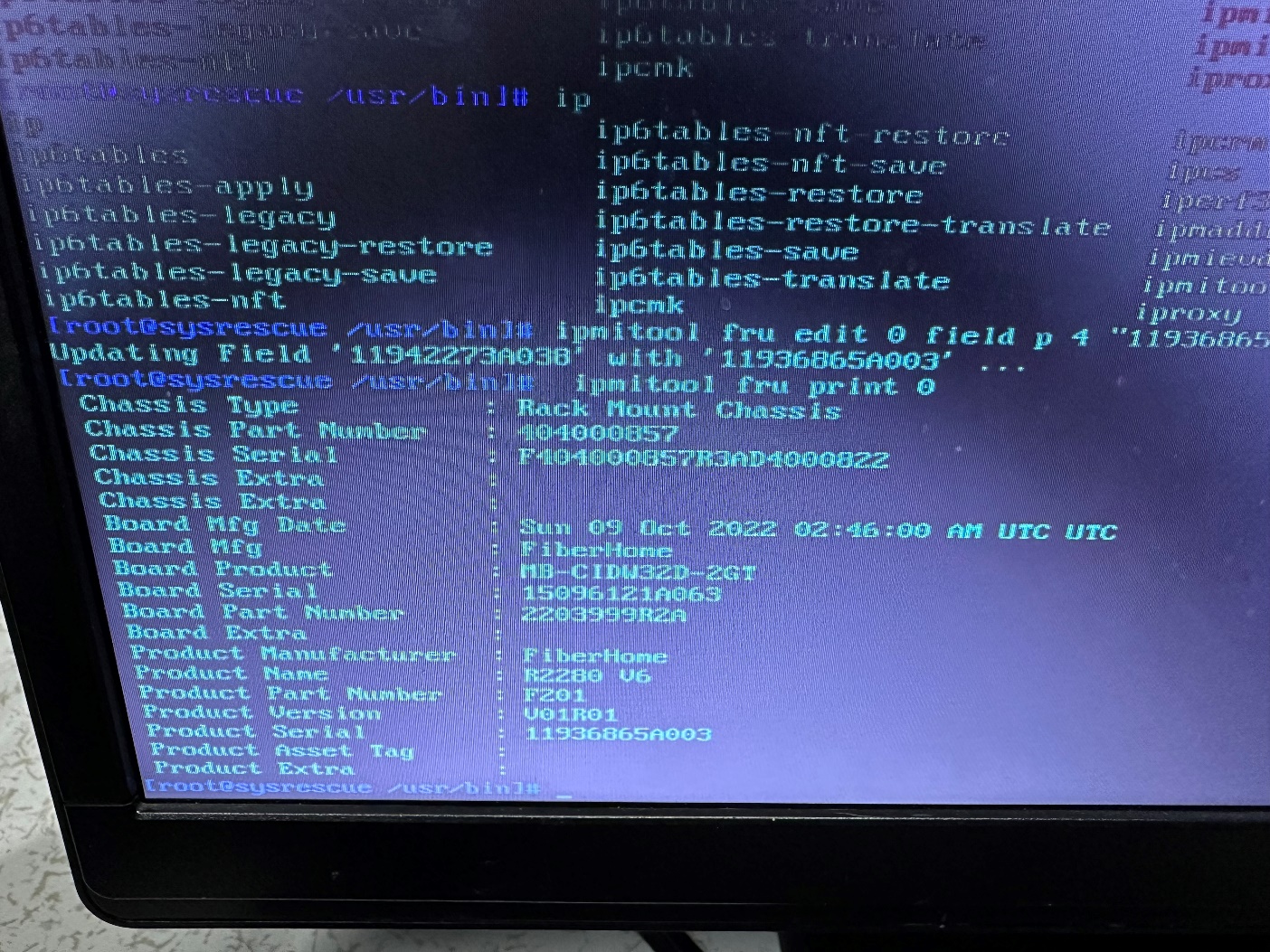
任务二更改主板SN步骤4:ipmitool fru edit 0 field b 2 “11936865A003”
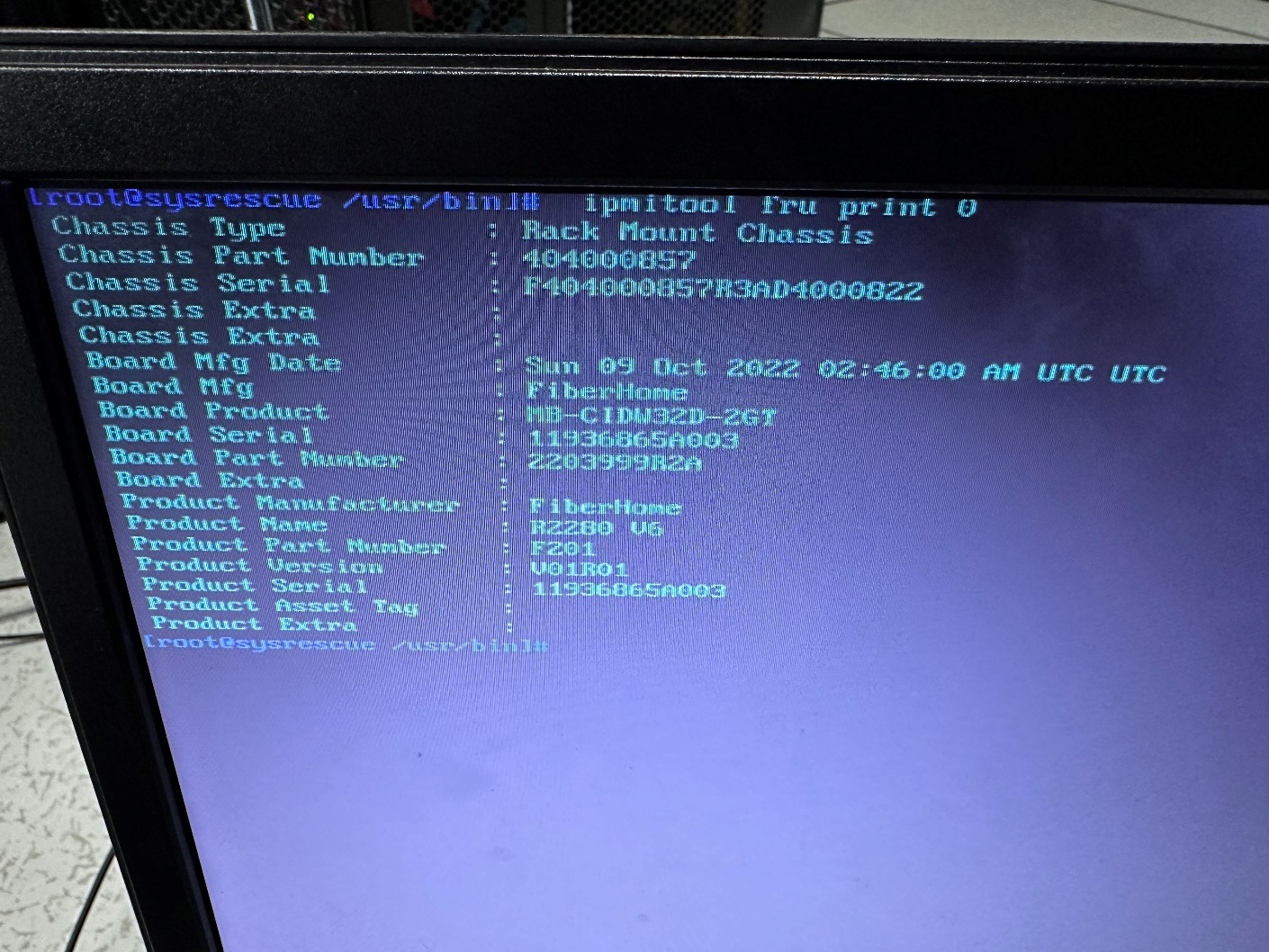
少数情况还可以更改机箱SN:[已脱敏] fru edit 0 field c 1 “11936865A003”
相关案例浙江徐工分享,几个工具网站https://www.tubatool.com/features/:
ipmitool fru print 0
# 打印当前的fru信息
ipmitool fru edit 0 field b 1 "Board Product Nama"
# 修改主板名称
ipmitool fru edit 0 field b 2 "".
# 修改主板序列号
ipmitool fru edit 0 field b 0 "Dela"
# 修改主板制造商
ipmitool fru edit 0 field b 3 "Dela"
# 修改主板部件号
ipmitool fru edit 0 field p 0 "Manufacturer Name"
# 修改产品制造商
ipmitool fru edit 0 field p 1 "
# 修改产品名字
ipmitool fru edit 0 field p 2 "Product-Name"
# 修改产品部件号
ipmitool fru edit 0 field p 3 "Product-Name"
# 修改产品版本号
ipmitool fru edit 0 field p 4 "Product-Name"
# 修改产品序列号
ipmitool fru edit 0 field p 5 "Product-Name"
# 修改产品资产标签
ipmitool fru edit 0 field c 0 "Product-Name"
# 修改机箱部件编号
ipmitool fru edit 0 field c 1 "Product-Name"
# 修改机箱机箱序列号
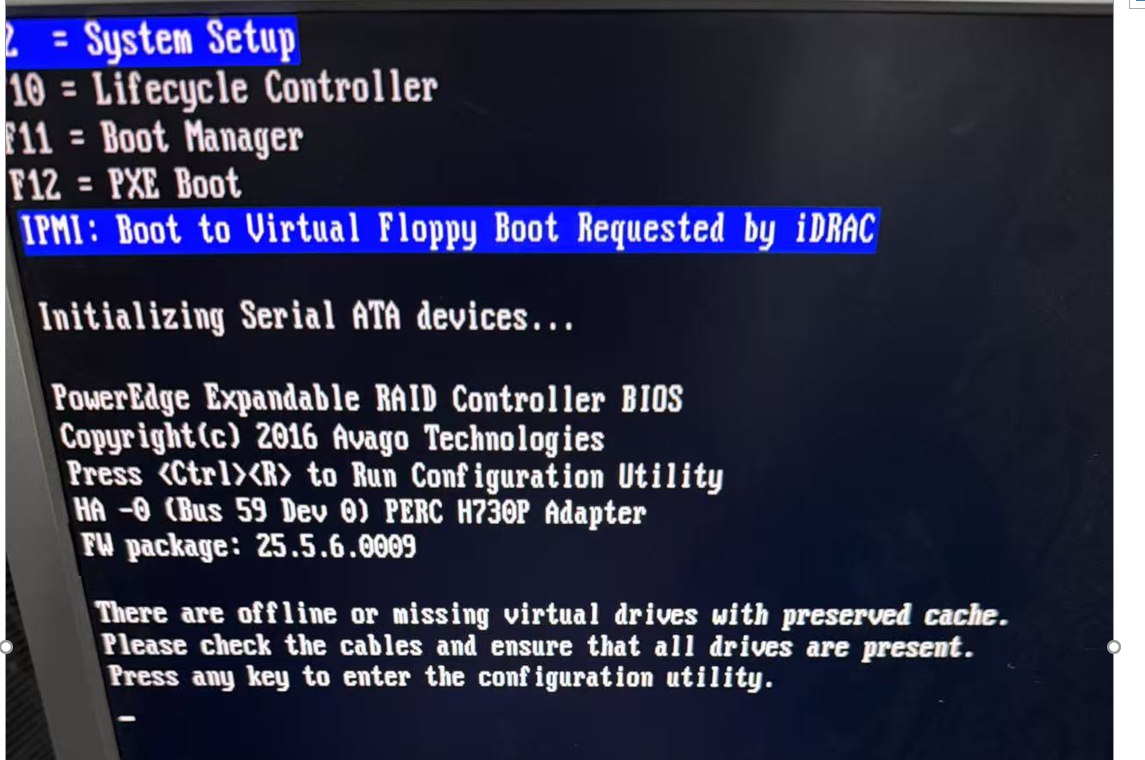
湖北彭工分享:浪潮Lsi9460-8i raid卡硬盘uncongfigured good无法创建raid0的解决步骤
注意:lsi9460-8i raid卡只能在UEFI模式下进入raid卡配置界面,传统模式无法配置。
针对遇到lsi9460-8i raid卡在bmc里查看有硬盘处于uncongfigured good状态,无法在BMC的raid控制器里直接创建raid0,需要重启服务器按del进入blos内配置。如下图:
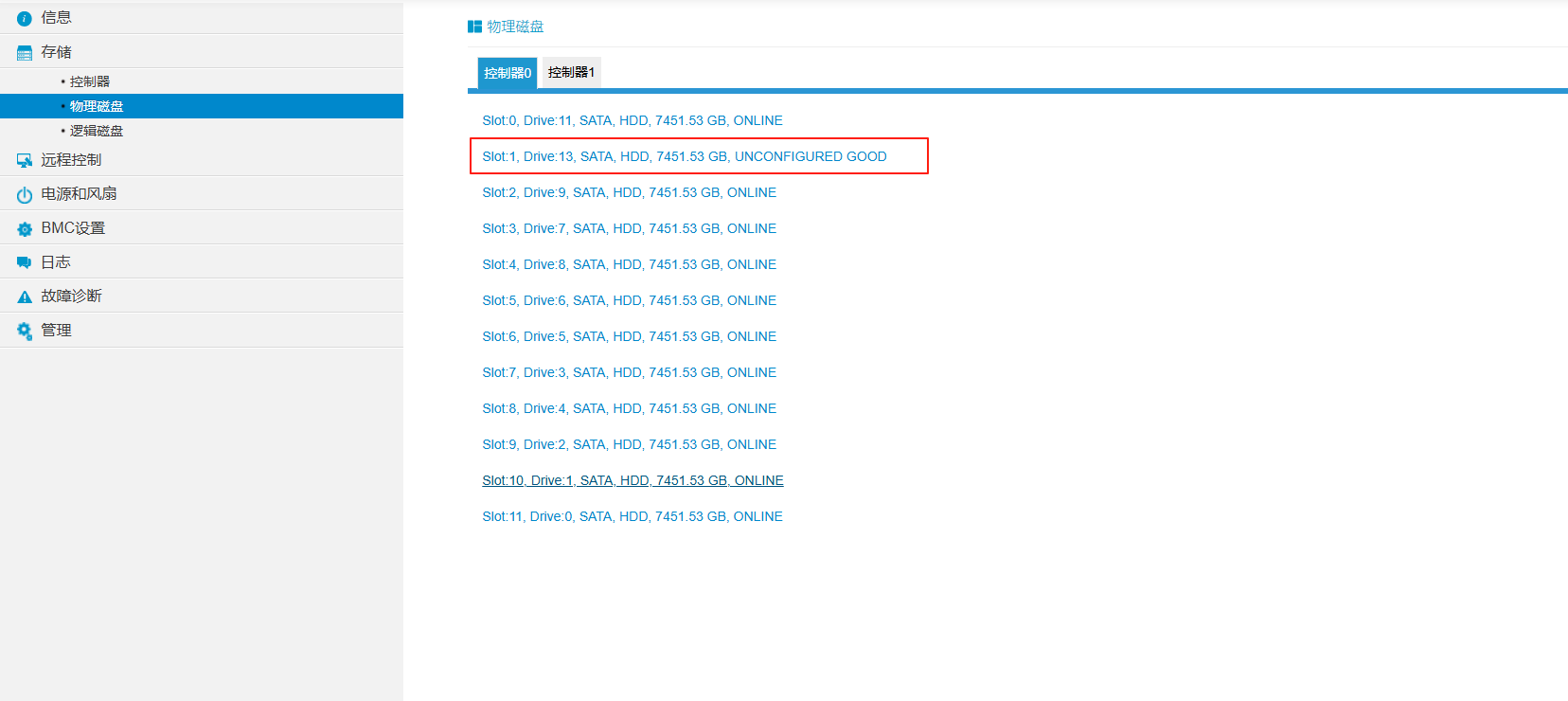
重启服务器,按del进入blos界面,选择advanced,把下图中所有传统启动模式更改为UEFI模式。
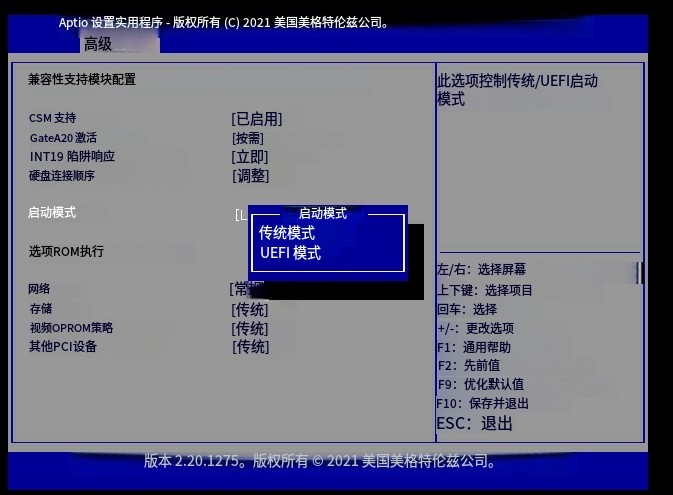
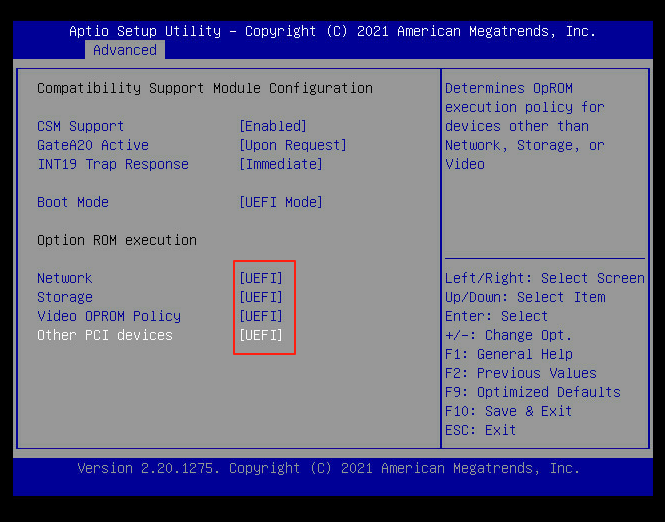 更改完成后按F10保存退出重启,重新进入blos界面。
更改完成后按F10保存退出重启,重新进入blos界面。
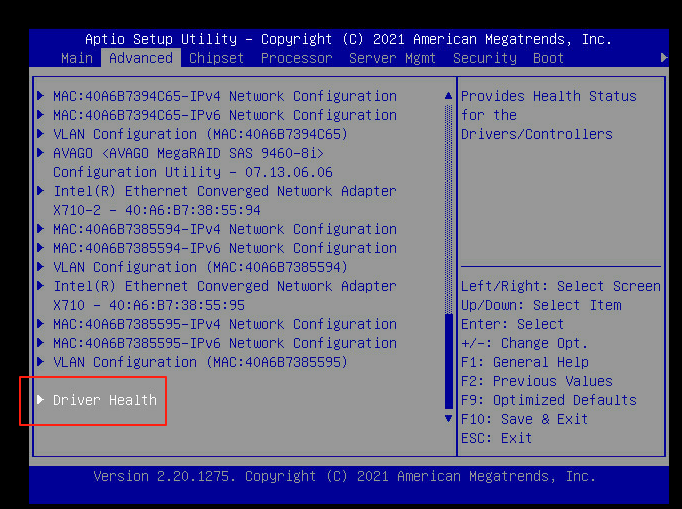
机器配置有两块9460-8i raid卡,发现只能发现一块,如下图

4、点击driver health,发现其中有一块9460-8iraid卡处于faied状态,如下图

5、移动光标至该选项,回车进入下图界面
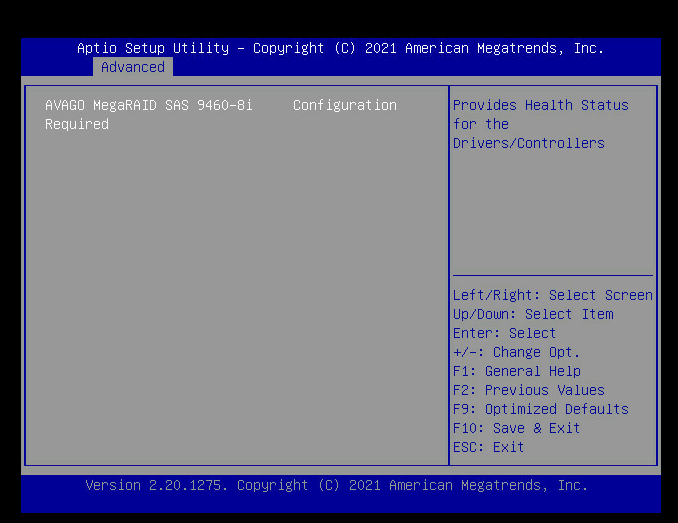
继续回车,进入下图界面,按回车跳出输入框,输入c或者ok,然后回车。

7、返回blos界面,发现第二张raid卡已找到,正常显示。

移动光标至该raid卡回车进raid卡配置界面,选择Configuration Managerent,发现没有创建raid选项,如下图

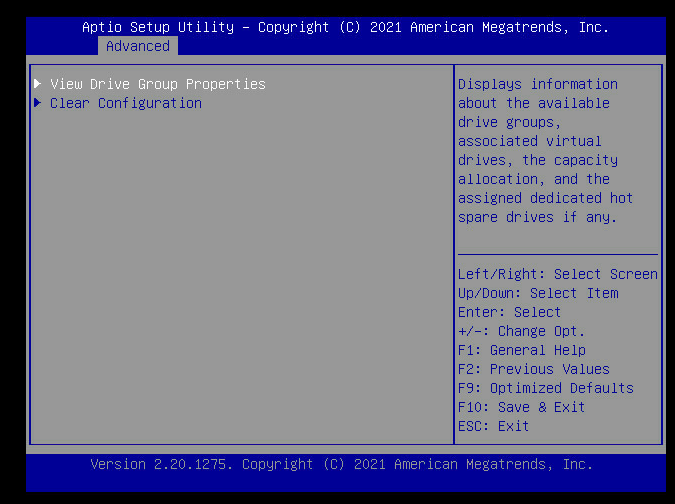
返回至如下界面,选择Discard Preserved Cache(丢弃保留的缓存)回车
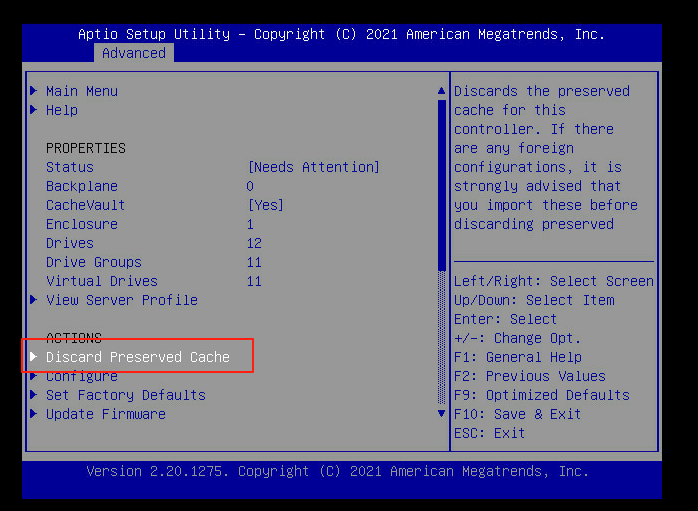
9、更改disabled至enabled,选择yes回车。
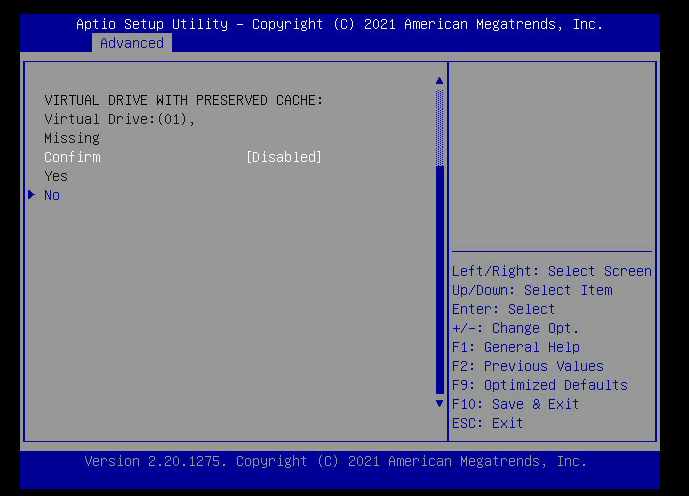
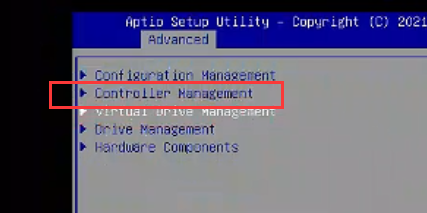
返回至如下界面,选择Configuration Managerent回车,发现已经可以正常创建raid。
纯DOS盘的制作方法:
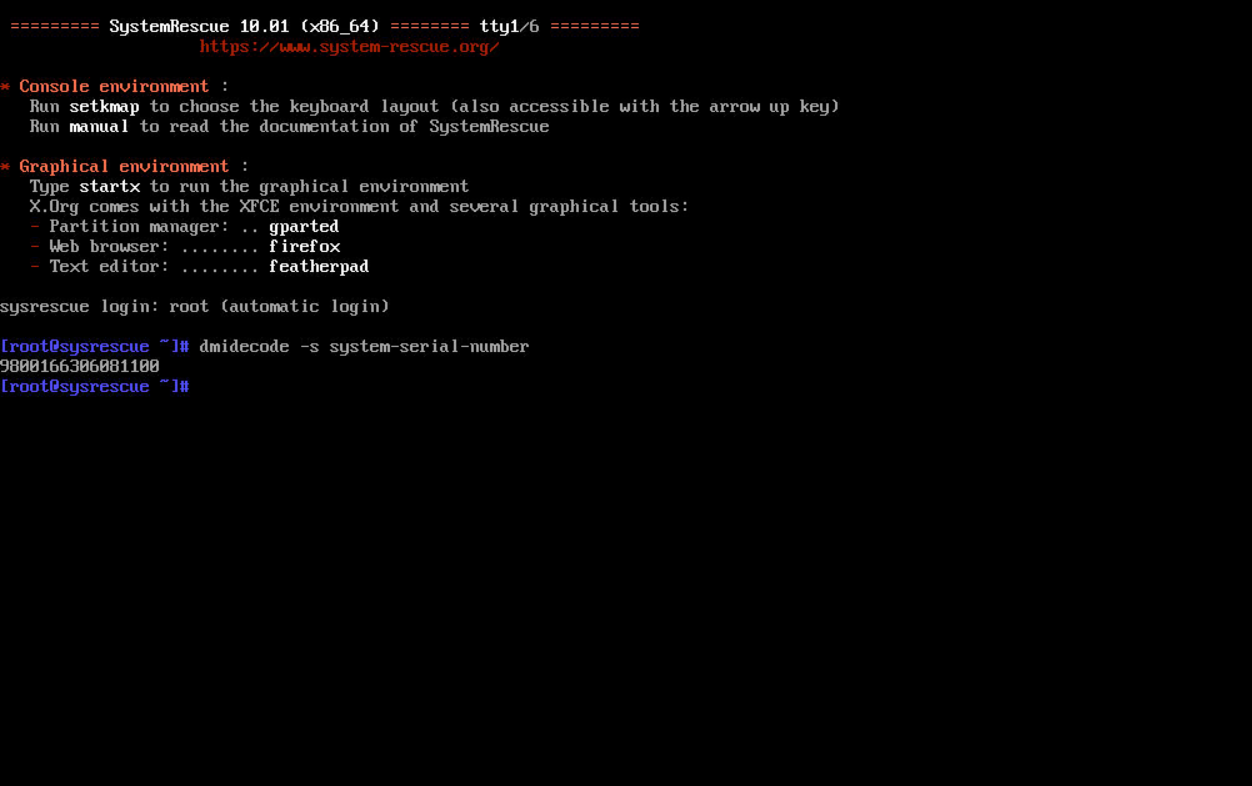
解决翼龙重装系统无法进行,dmidecode -s system-serial-number,提示:To be filled by 0.E.M.
制作纯dos刷新bios工具:格式化u盘位msdos
如下图中,这种主板不正常,很多字段显示:To be filled by 0.E.M.
需要使用dmicfg工具进行更改,选择最左侧的edit,左侧的3项都要改,所有的Serial Number都要改。

Bios中显现不会更新,系统中会更新。
纯dos引导方法2:
ventoy-1.1.11工具可以不格式化U盘多个ios分别引导,但是有个新问题,无法引导纯dos。
测试出来一个嵌套引导的方法:
1、用ventoy引导杏雨梨云ios,启动菜单选二级菜单,搜索DIYRUN目录,引导纯dos(当然前提是早先创建目录和写入文件)。
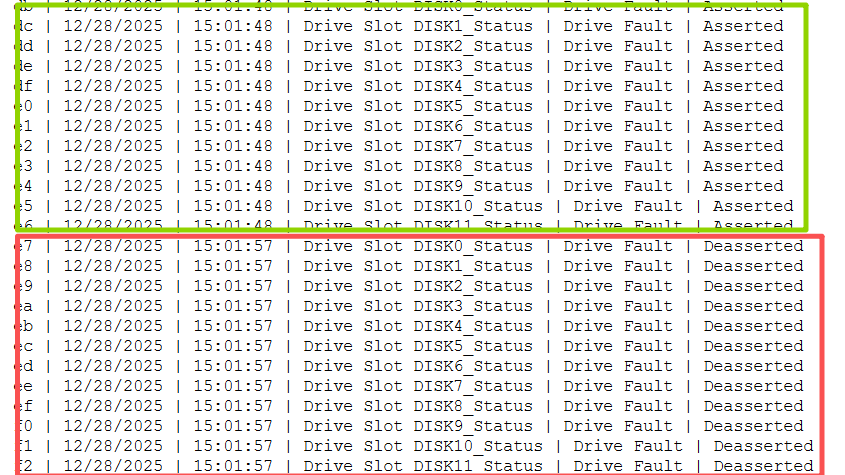
浪潮 NF5280M5 设备序列号:[已脱敏]。日志中所有硬盘全部掉线,短暂时间恢复。现场所有硬盘都亮故障灯,可以强制上线解决。
9秒前全部不在位,9秒后全部在位了。日志里阵列卡、硬盘背板都是正常的。需要到现场看一下。Ctrl+A进入阵列卡配置界面,可以强制把硬盘拉起来。
如下为带外日志:
如下为系统内日志:
Ctrl+A进入阵列卡配置界面,可以强制把硬盘拉起来。强制拉上线
相关案例:更换阵列卡后无法进入系统,登录阵列卡配置界面提示CC进度(一致性检查):
更换阵列卡无法进入系统。登录真题卡界面,看到CC一致性验证的进度是71%不动,他硬拔下所有硬盘,勾选enable stop CC,问题解决。后问题复现,需要跟换硬盘。
关于电源的几个常见问题:

曙光、浪潮服务器电源故障,更换无效,空开跳闸,无法合闸——》原因:电源短路,更换电源后正常;
dell的服务器电源空载是常亮,可以用于判断备件是否可用;
接回机器这个灯红色报警,正常的电源空载测试电源灯会闪烁绿灯

windows server中通过powershell查看硬盘sn
启动powershell,窗口中输入如下命令:
Get-WmiObject -Namespace "root\Microsoft\Windows\Storage" -Class MSFT_PhysicalDisk | Select-Object FriendlyName, SerialNumber, MediaType
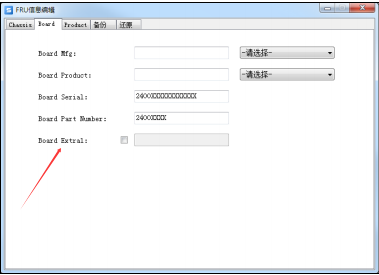
案例分享:福建董工:中科可控信创主机,硬盘故障,更换后无法识别到,后更换raid卡后主板通电无自检,更换主板依旧,主板型号:原机:65N32-US/R-HD===替换件:65N32-US/R,推测不兼容,实际需要更新固件暂时正常。
最后找原厂,需要刷新FRU信息。具体如下:
更换完中科可控H620-G30主板,进行完配置后,发现带外无法识别NVME盘的固件版本以及容量,系统下也识别不到盘。

原因分析
主板的FRU里的扩展字段没有进行更新。
解决方法
刷新主板的FRU里的扩展字段。把Board Extral这一项刷成1001111。
相关案例:同样机型更换硬盘后依旧无法识别,更换旁边空硬盘槽位后正常。
Dell服务器不要再LC中配置阵列卡,会造成配置丢失:lc配置raid会覆盖原有的raid,在阵列卡界面做回raid,不要init初始化。
lc的raid是给新机部署的,不是维护工具。lc就是类似带外的简化版,可以部署系统查看日志更新固件
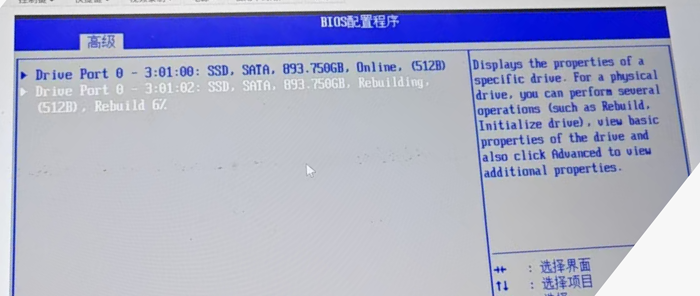
设备序列号:[已脱敏],硬盘预故障,更换后故障依旧,重启带外后正常。
故障现象:硬盘提示预故障Predicting Failure。
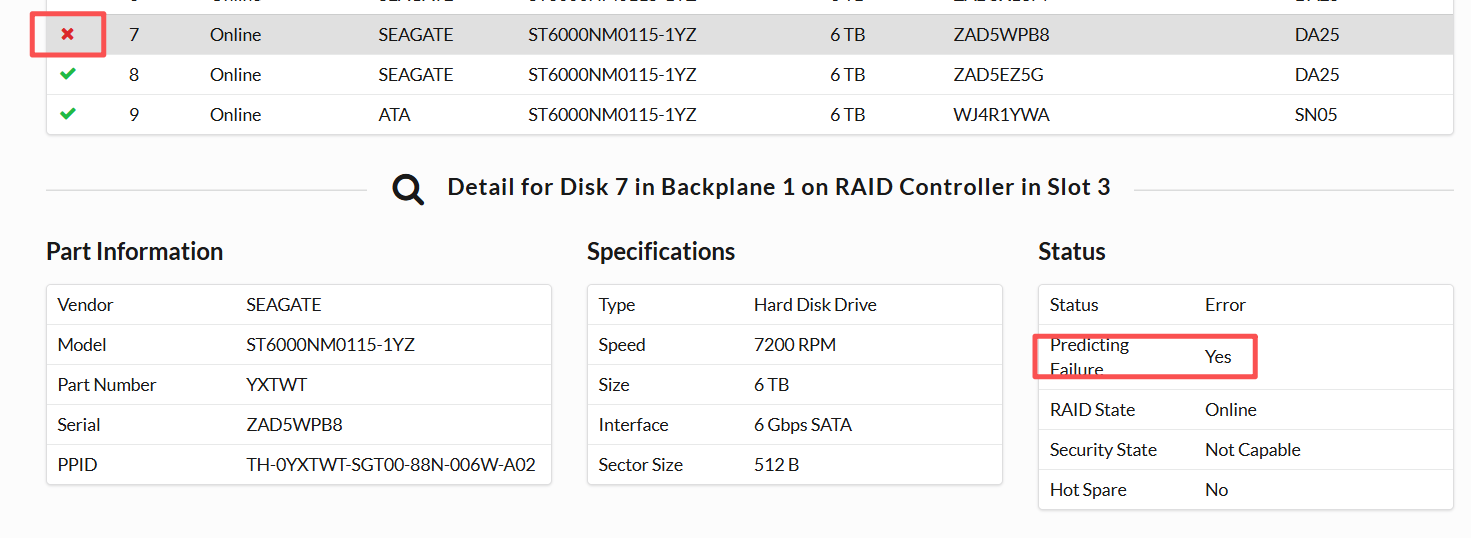
更换硬盘后rebuild完成后故障依旧,带外依旧提示故障。
重启带外后正常。
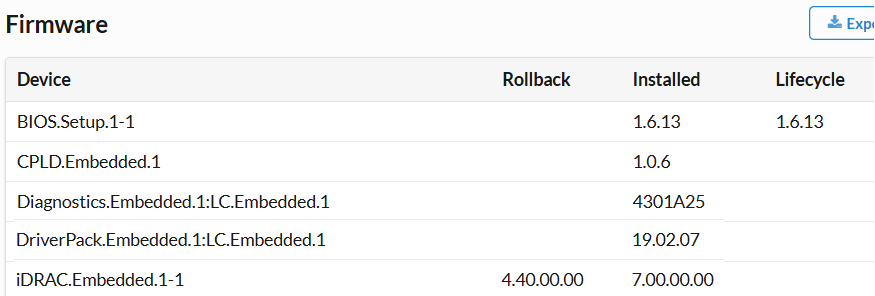
相关版本信息:BIOS.Setup.1-1版本:1.6.13,Lifecycle 版本1.6.13,CPLD.Embedded.1版本1.0.6,iDRAC.Embedded.1-1Rollback版本4.40.00.00,安装的版本7.00.00.00。
通过光纤配线架ODF现场图片,判断光纤接头的种类:
其中ODF中的FC耦合器一般用方形耦合器代替
红光笔:比如TFN充电红光笔,用650nm波长快速定位断点,适合单模/多模光纤。俗称打光笔。
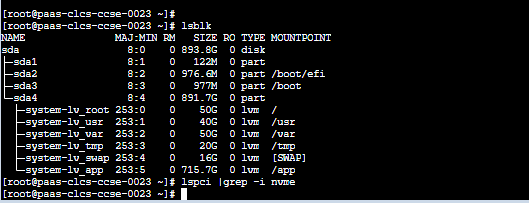
通过命令查看挂载点硬盘的序列号:[已脱敏],浪潮NF5466M5





smartctl -A /dev/sdc
lsblk -o NAME,MODEL,SERIAL,TRAN,MOUNTPOINT | grep -V 'Ioop'
确定nvme序列号、盘符对应关系的命令,需要带外查看SN用排除法确定。
[teledb@[内网主机]~]$lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 447.1G disk
-sdal -sda2 8:1 122M part
-sda3 8:2 488M part /boot/efi
8:3 488M part /boot
sda4 8:4 446G part
-system-lv root 253:0 60G lvm
-system-lv_swap 253:1 16G lvm [SWAP]
system-lv_app 253:2 370G lvm /app
nvmeln1 259:2 5.8T 0 disk /data2
nvme2n1 259:3 5.8T 0 disk /data3
nvme3n1 259:0 5.8T disk /data4
[root@[内网主机] teledb]# nvme list
Node SN:[已脱敏] Namespace Usage Format FW Rev
---------------- -------------------- ---------------------------------------- --------- -------------------------- ---------------- --------
/dev/nvme0n1 S6BPNX0TB00001 Samsung SSD 980 PRO 1TB 1 512.11 GB / 1.02 TB 512B + 0B 5B2QGXA7
/dev/nvme1n1 NVME-CT2000P3PSSD8 Crucial P3 Plus 2TB 1 2.00 TB / 2.00 TB 512B + 0B P9CR304
[root@[内网主机] teledb]# lsblk --output NAME,KNAME,SIZE,MODEL,SERIAL,TYPE | grep -i nvme
nvme1n1 nvme1n1 5.8T MO006400KWVND [硬盘S/N已脱敏] disk
nvme2n1 nvme2n1 5.8T MO006400KWVND [硬盘S/N已脱敏] disk
nvme3n1 nvme3n1 5.8T MO006400KWVND [硬盘S/N已脱敏] disk
[root@[内网主机] teledb]# blkid |grep -i nvme
/dev/nvme1n1: LABEL="data" UUID="bd80caaa-d120-4e35-93a3-2ac486a569f4" TYPE="xfs"
/dev/nvme2n1: LABEL="data" UUID="39136627-f8e4-4fc8-a14f-e0d7b19199b9" TYPE="xfs"
/dev/nvme3n1: LABEL="data" UUID="bd71584f-9a5d-4c76-96b4-dae32057c63e" TYPE="xfs"
通过UUID确定盘符对应关系
[root@[内网主机] teledb]# cat /etc/fstab
UUID=EC40-5A7F /boot/efi vfat defaults 0 1
UUID=1719e273-0724-4fcf-be54-2d591c758c6e /boot ext2 defaults 0 1
UUID=5f2b6d0d-f6d9-4159-9d89-73b260bc12c7 / xfs defaults 0 1
UUID=467c3e3c-e136-4df8-a755-22cb59953ee9 /dev/mapper/system-lv_swap swap defaults 0 0
UUID=f1c5ad9f-a8e0-4f69-bbd3-4c52990acb3c /data1 xfs rw,noatime,nodiratime,noikeep,nobarrier,allocsize=100M,attr2,largeio,inode64,swalloc 0 0
UUID=bd80caaa-d120-4e35-93a3-2ac486a569f4 /data2 xfs rw,noatime,nodiratime,noikeep,nobarrier,allocsize=100M,attr2,largeio,inode64,swalloc 0 0
UUID=2ec56145-68f4-4ed1-b53b-3bc60fbc768b /app xfs defaults 0 0
UUID=39136627-f8e4-4fc8-a14f-e0d7b19199b9 /data3 xfs rw,noatime,nodiratime,noikeep,nobarrier,allocsize=100M,attr2,largeio,inode64,swalloc 0 0
UUID=bd71584f-9a5d-4c76-96b4-dae32057c63e /data4 xfs rw,noatime,nodiratime,noikeep,nobarrier,allocsize=100M,attr2,largeio,inode64,swalloc 0 0
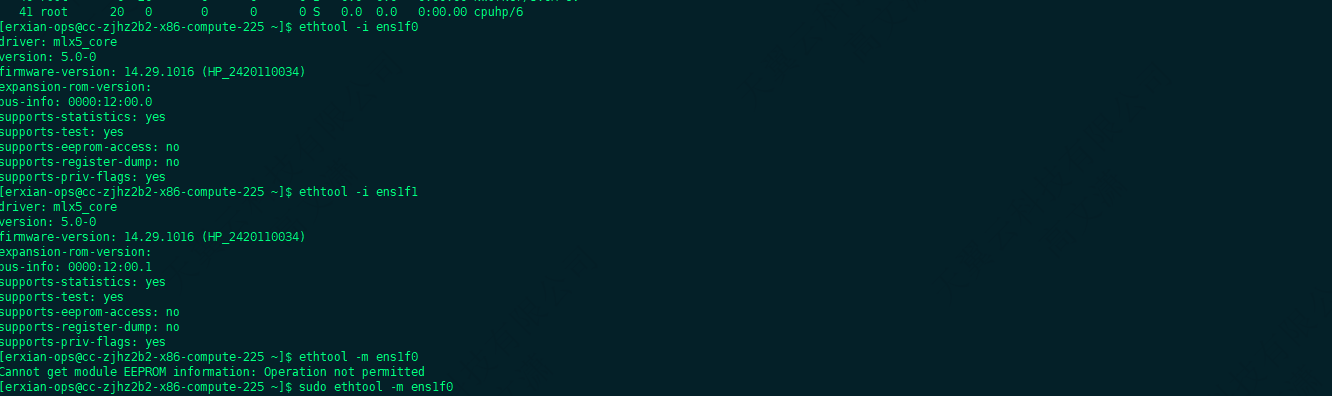
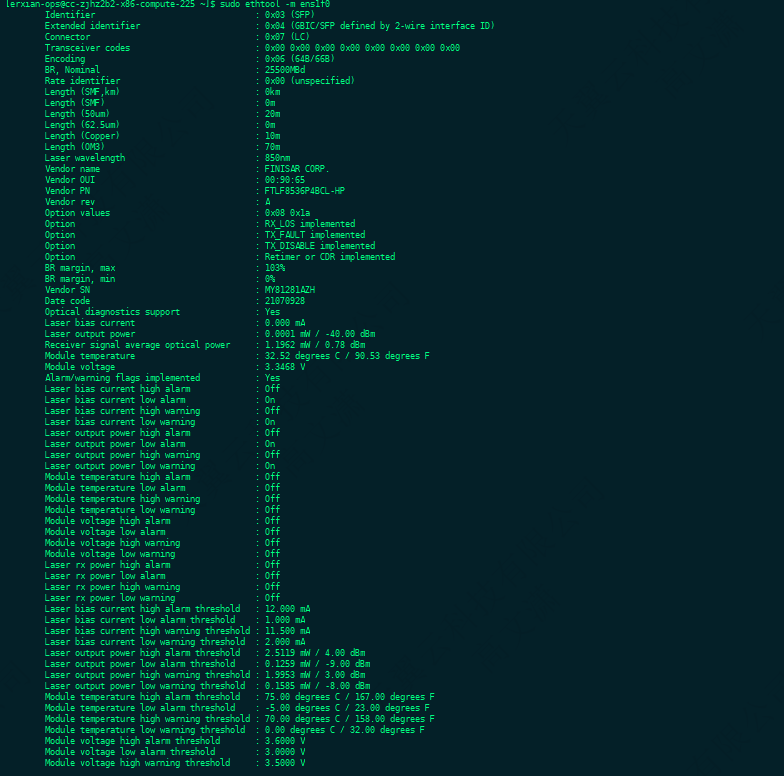
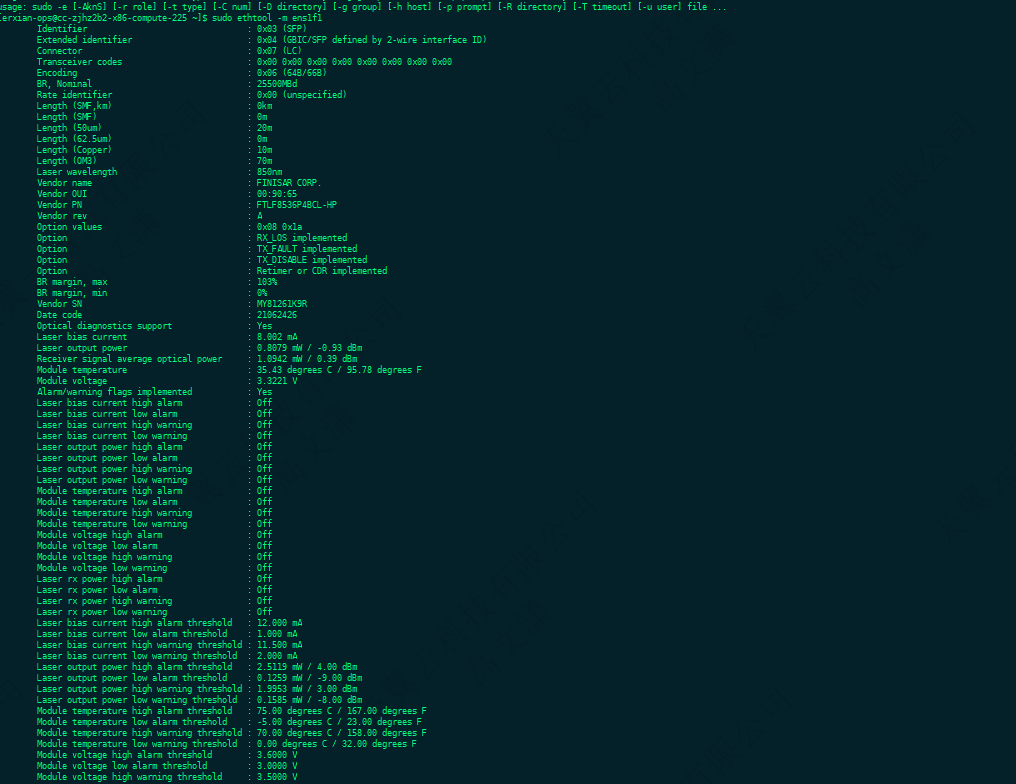
Linux中通过命令查看网卡和光模块信息
ethtool -i ens1f0
ethtool -i ens1f1
ethtool -m ens1f0
ethtool -m ens1f1

ethtool ens1f0 | grep -E "Link detected|Speed|Duplex"
ethtool ens1f1 | grep -E "Link detected|Speed|Duplex"
案例分析和启示:维修中新产生的故障与近期操作有关。
超聚变更换阵列卡后提示:The SAS or PCIe cable to rear disk backplane (BC82THBAB) PORT_A is incorrectly connected.原因和解决方法riser没插到底,下架重新插后正常。
阵列卡报错,更换后报很多错误,后来发现riser没有没有插紧,用力压有反馈的声音:超聚变5288 V5
案例分析和启示:不能完全以带外作为故障恢复的一句,现在发现中兴、超聚变、Dell都出现过更换备件后问题未解决。分一下3中情况:

彻底解决需要更换备件后重启带外;
拔下更换备件,申请关机重启后再更换备件;
更换备件后关机、拔下电源静置一会儿(与带外重启类似,更彻底)
对应具体案例:设备厂家:中兴 R5300 G4X 设备序列号:[已脱敏]。故障现象:nvme 4 has failure. Asserted. 更换备件后未完全解决。
相关案例:超聚变硬盘故障更换后提示:轻微告警,拔下后重启带外,再插入硬盘后正常
案例分享:更换cmos电池,注意电池座底下负极的接触片王上提一点,避免接触取电垫片无弹性更换电池后性接触不良。
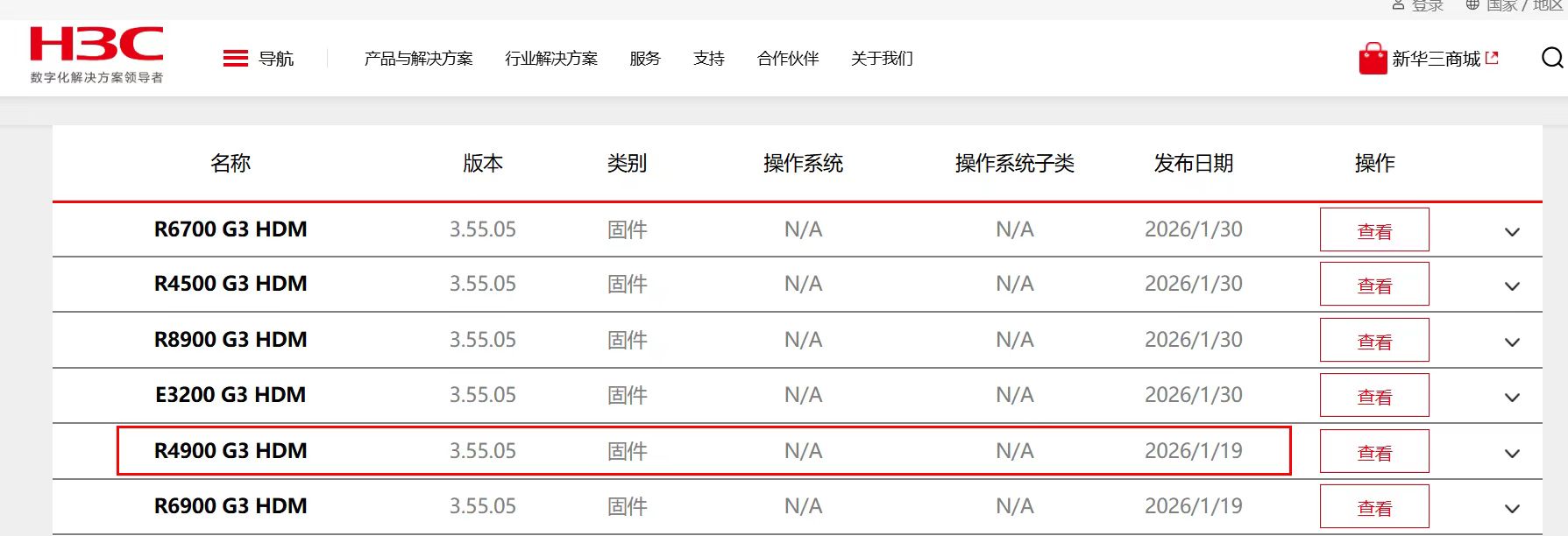
湖北彭工分享:H3C版本解决带外不通问题,日志经常弹出,胡乱报日志进3000条,一堆日志。刷新固件解决,具体版本如下:
华三4900 G3的bmc经常弹出日志,可以升级到3.55.05版本,其它版本试过无效
案例分享:超聚变 RH5288 V3,序列号:[已脱敏],保修故障:异常宕机
到达现场确认故障现象:两个电源灯不亮,机箱面板指示灯显示9,代码“9”可能对应特定模块(如CPU、内存或电源)的异常,带外报错:Power supply failure。
预备进行最小化测试,发现故障原因:主板供电有烧毁痕迹。
这个案例是一个标准的确定故障的思路,和故障判断的指引,值得给大家分享:现场确认故障——》查看面板指示灯——》查看带外报错信息——》最小化测试——》查看主板元器件状态




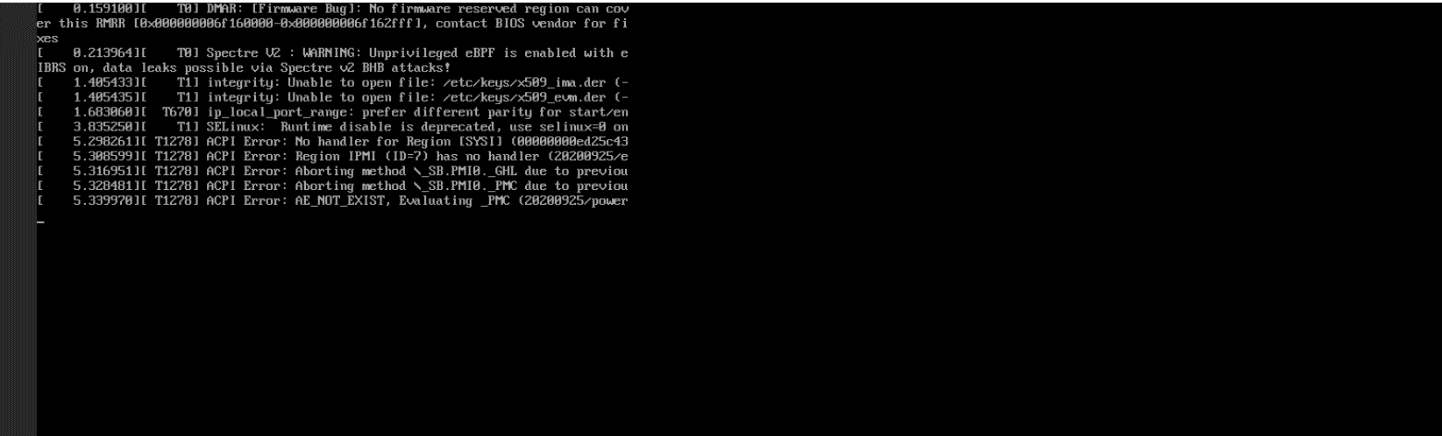
案例分享:ctyunos默认不会有Login的登录界面,启动后要手动ctrl + alt + f2才能看到login,在第一张图片进行按键操作出现登录界面。错误认为启动死机,耽误时间比较多。
同时发现:DELL PowerEdge R740 设备序列号:[已脱敏],杏雨梨云的启动win PE无法安装设备驱动,但可以在AIDA中查看到网卡信息(通过未安装设备的ID识别),但自带的AIDA运行时蓝屏,需要使用徐晓龙分享的AIDA版本。后续分享此版本,并进行压测查看是否可以跑慢CPU。
案例分享:超聚变 RH2288H V5 设备序列号:[已脱敏]
工程师:这个工单管业务的老师说对业务没有影响,硬盘读写都正常,我现场看也没有亮硬盘故障灯和服务器故障灯。
老师,经过我们二线的分析。硬盘确认异常后5分钟内自动恢复,恢复后这块硬盘就不提示错误了。下次换成另外一块硬盘提示异常,同样5分钟自动恢复。都是轻微、次要提示信息。
例如:
The disk Disk9 state is abnormal (SN:[已脱敏]). 2025/10/21 22:47 Deasserted
The disk Disk9 state is abnormal (SN:[已脱敏]). 2025/10/21 22:45 Asserted
这是一种隐患,最好可以关键检查一下阵列卡和数据线。但如果您不方便停业务,而且数据有备份,可以不处理。因为这个现象已经持续3年了。估计误报或者带外dug的可能性更大。
最后确定的原因,所有的硬盘都有如下信息:
dump_info\AppDump\StorageMgnt\RAlD_Controller_Info.txt
Media Error Count : 0
Prefail Error Count : 0
Other Error Count : 4078
最后按照客户的意愿,换了disk6,有Media Error Count : 90
案例分享:NF5280M5服务器:LSI9460-8i raid卡硬盘 uncongfigured good状态在带外下无法创建raid0的解决步骤
登录带外硬盘状态如下所示:
正常情况下通过以下步骤可以解决:
点击存--《存储》菜单下的--《逻辑磁盘》---然后点右下角的《创建虚拟磁盘》如下图所示:
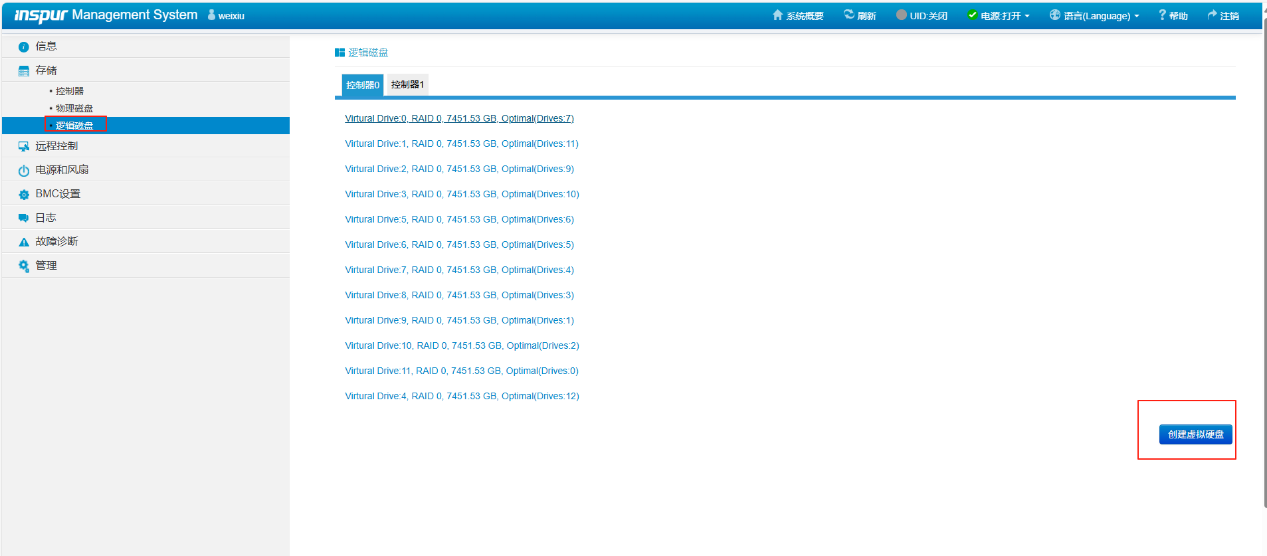
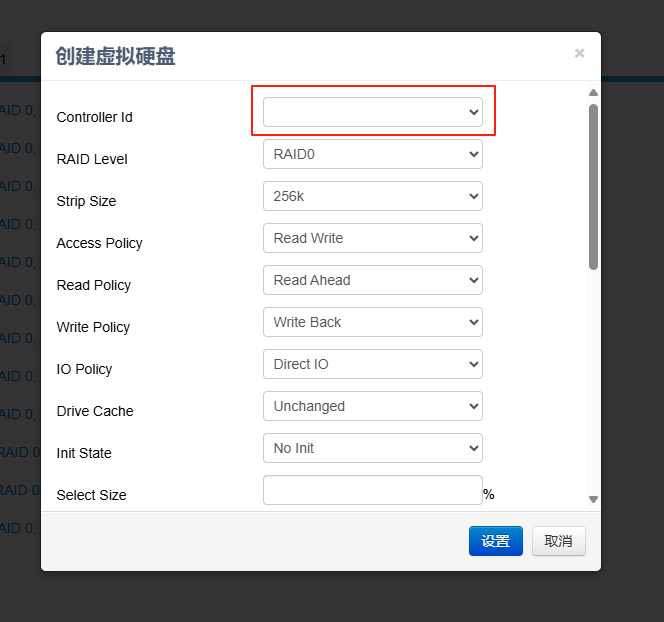
在弹出的窗口中《Controller ID》处选硬盘对应的阵列卡。
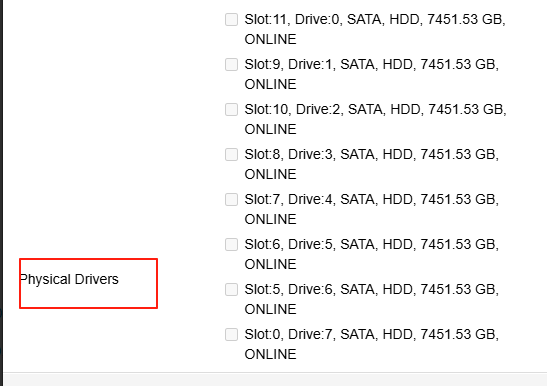
到最下面物理磁盘处选择对应的物理磁盘,然后确认,等待2-3分钟后会创建成功。
特殊情况下,在带外下按以上步骤提示创建成功,但并不生效,解决方法如下:
<注意:NF5280M5服务器:LSI9460-8i RAID卡无法单独进入阵列配置模式,需要调整BIOS中的模式,在BIOS中创建阵列>具体操作如下:
另NF5280M5服务器在自检界面会反复重复,以及停留在图2界面较长时间,需要耐心等待

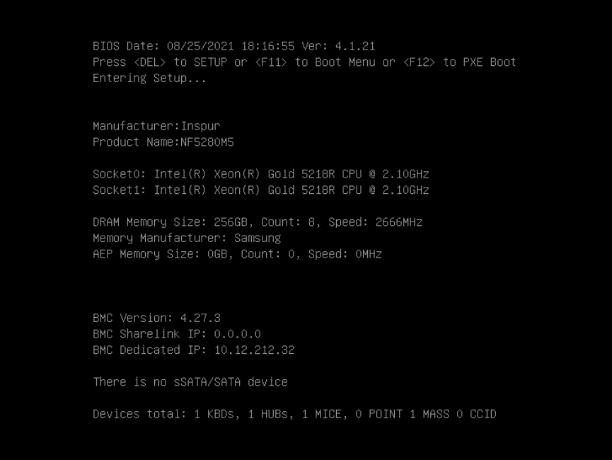
重启服务器,按del进入blos界面,选择advanced,进入CSM Configuration 选项,如下图所示:
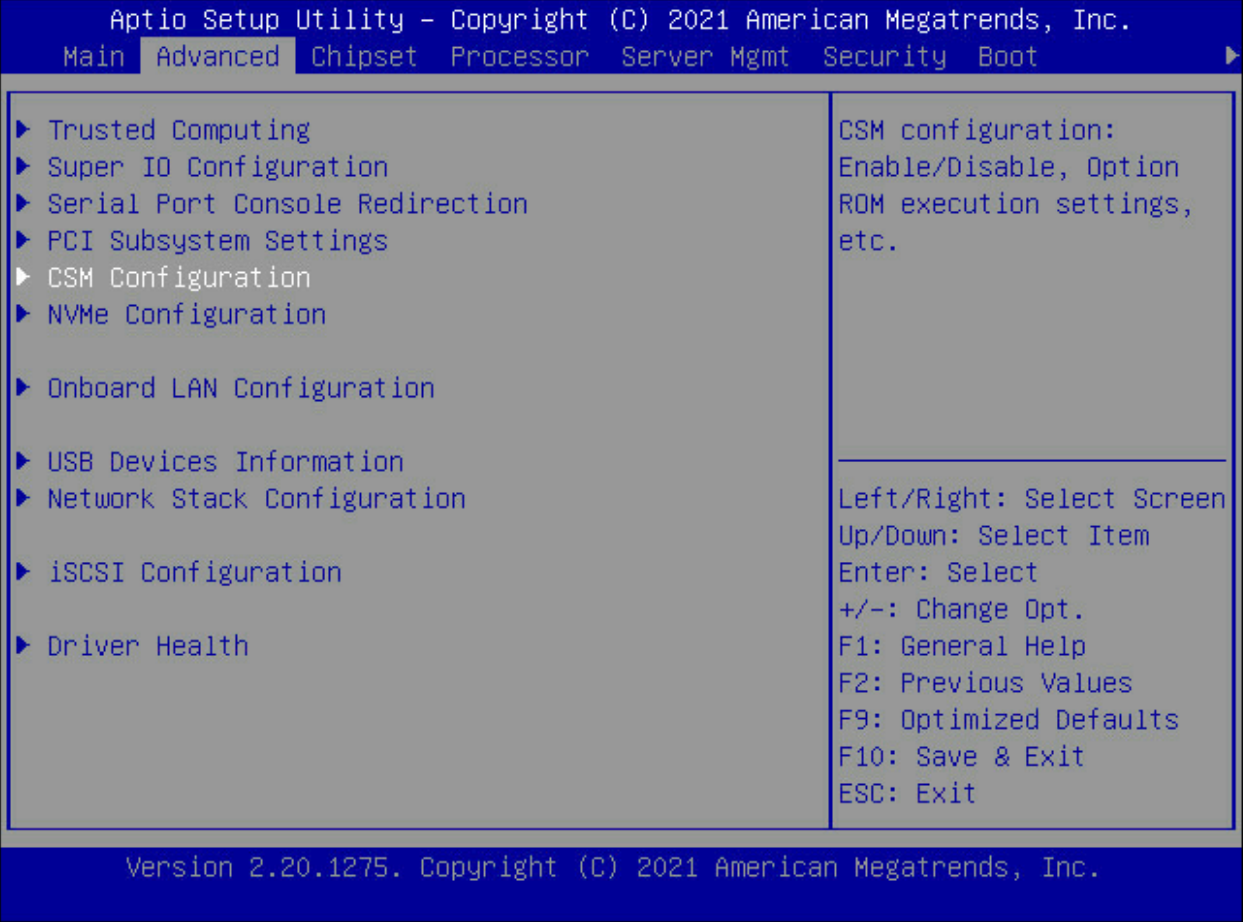
把Boot Mode 、Network、Storage、Video OPROM Policy、Other PCI Devices模式由原先的Legacy 改为:UEFI。如下图所示:
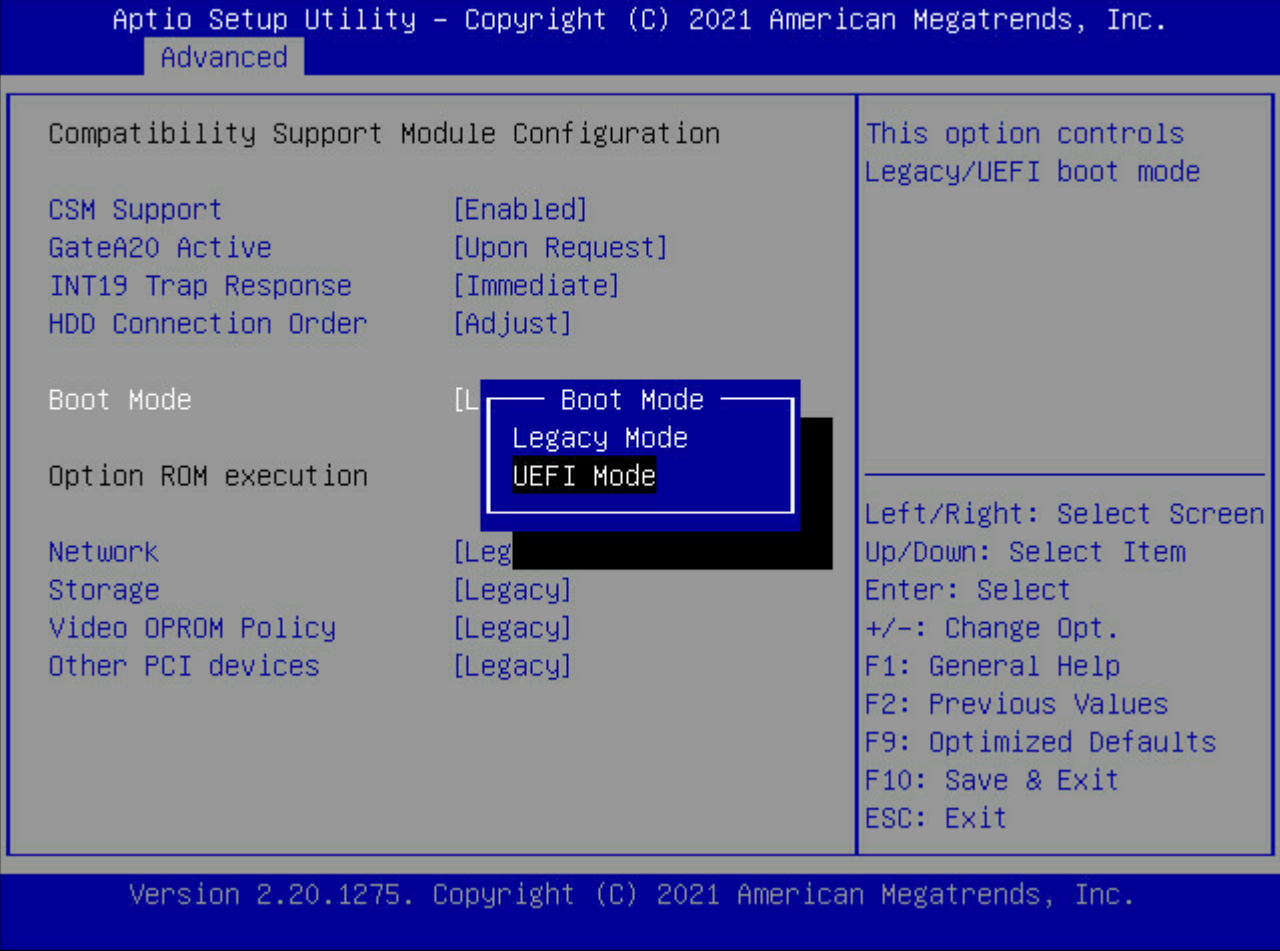

更改完成后按F10保存退出并重启,重新进入blos界面。
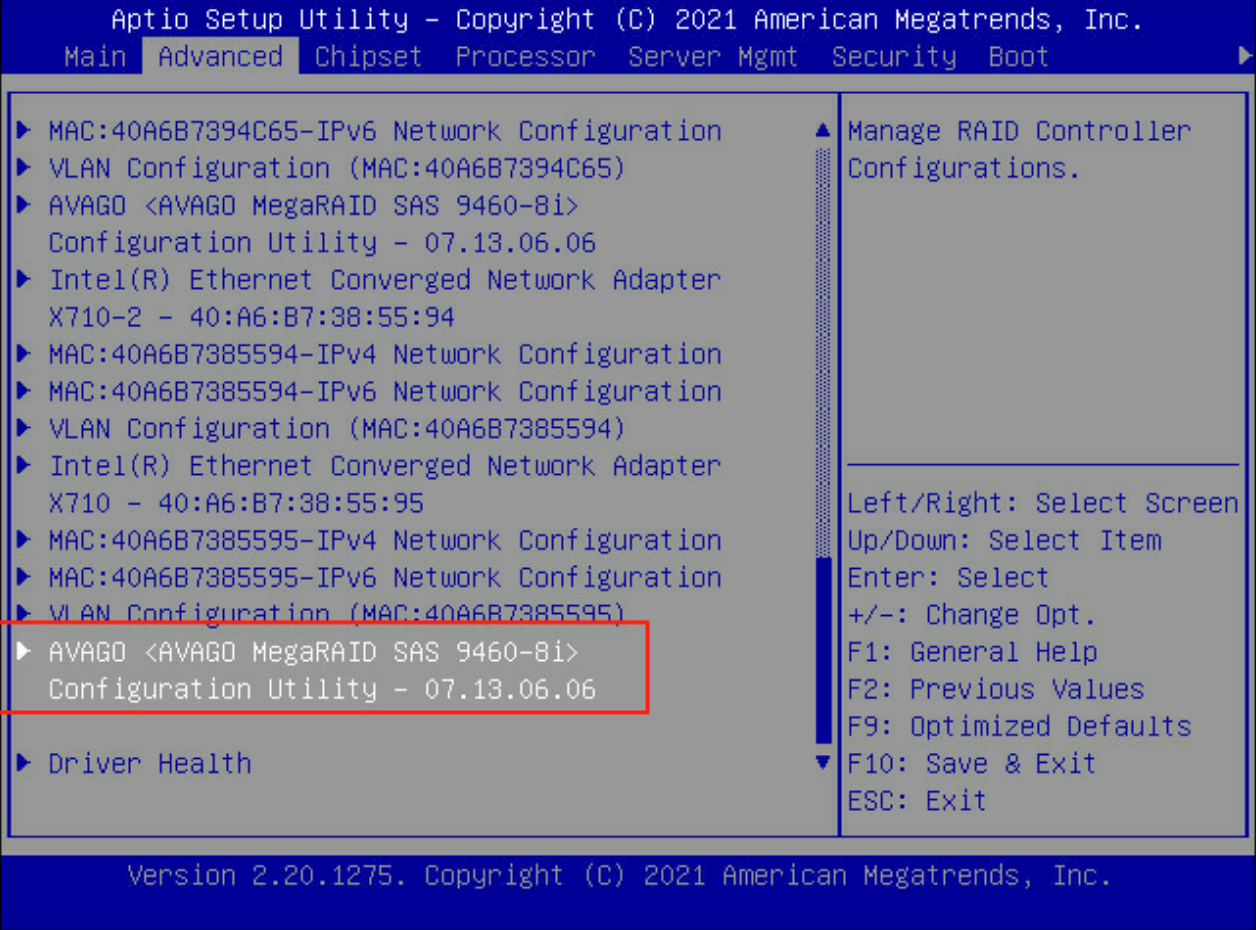
进入Advanced 选项,(当前服务器配置有两块9460-8i raid卡,发现只能发现一块,如下图

光标移动到Driver Health,发现其中有一块9460-8i raid卡处于Faied状态,如下图

移动光标至该选项,回车进入下图界面
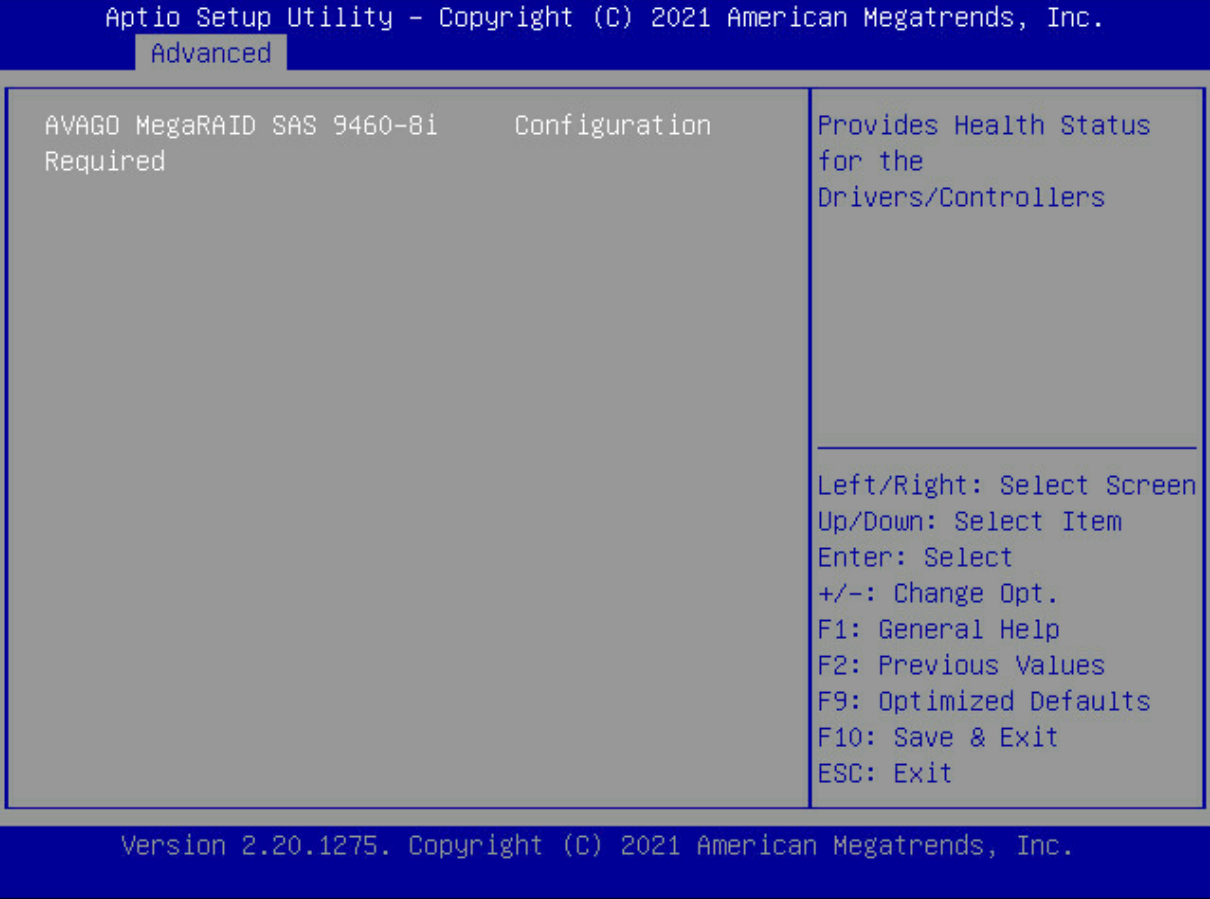
继续回车进入下图界面,按回车跳出输入框,输入c或者ok,然后回车。
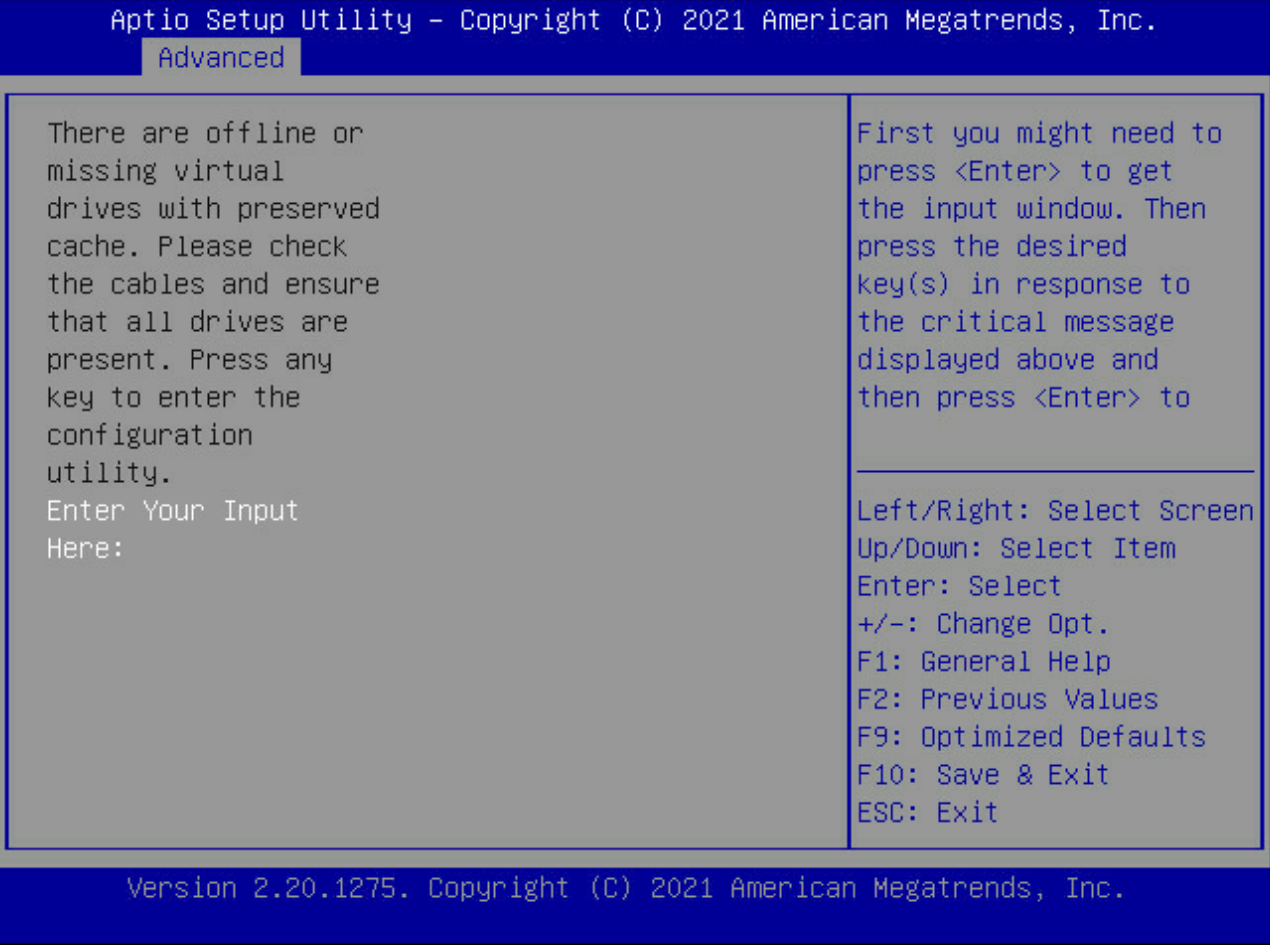
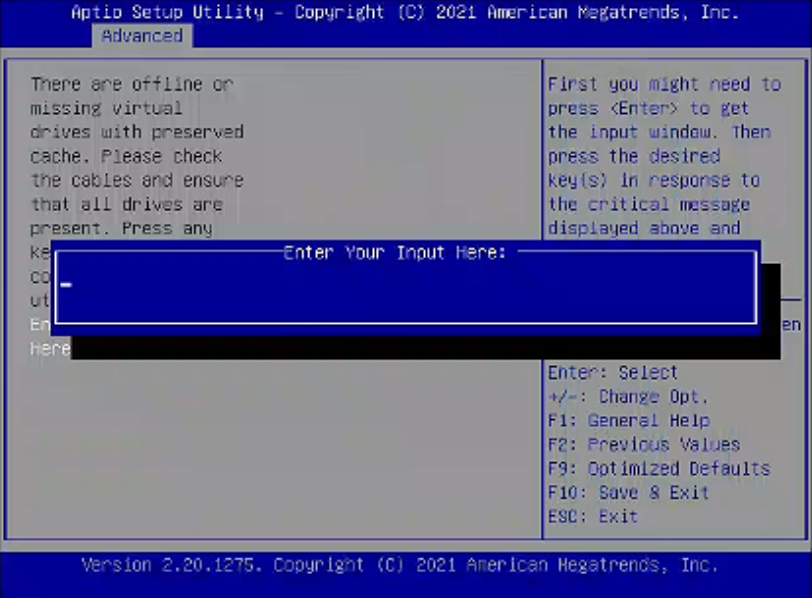
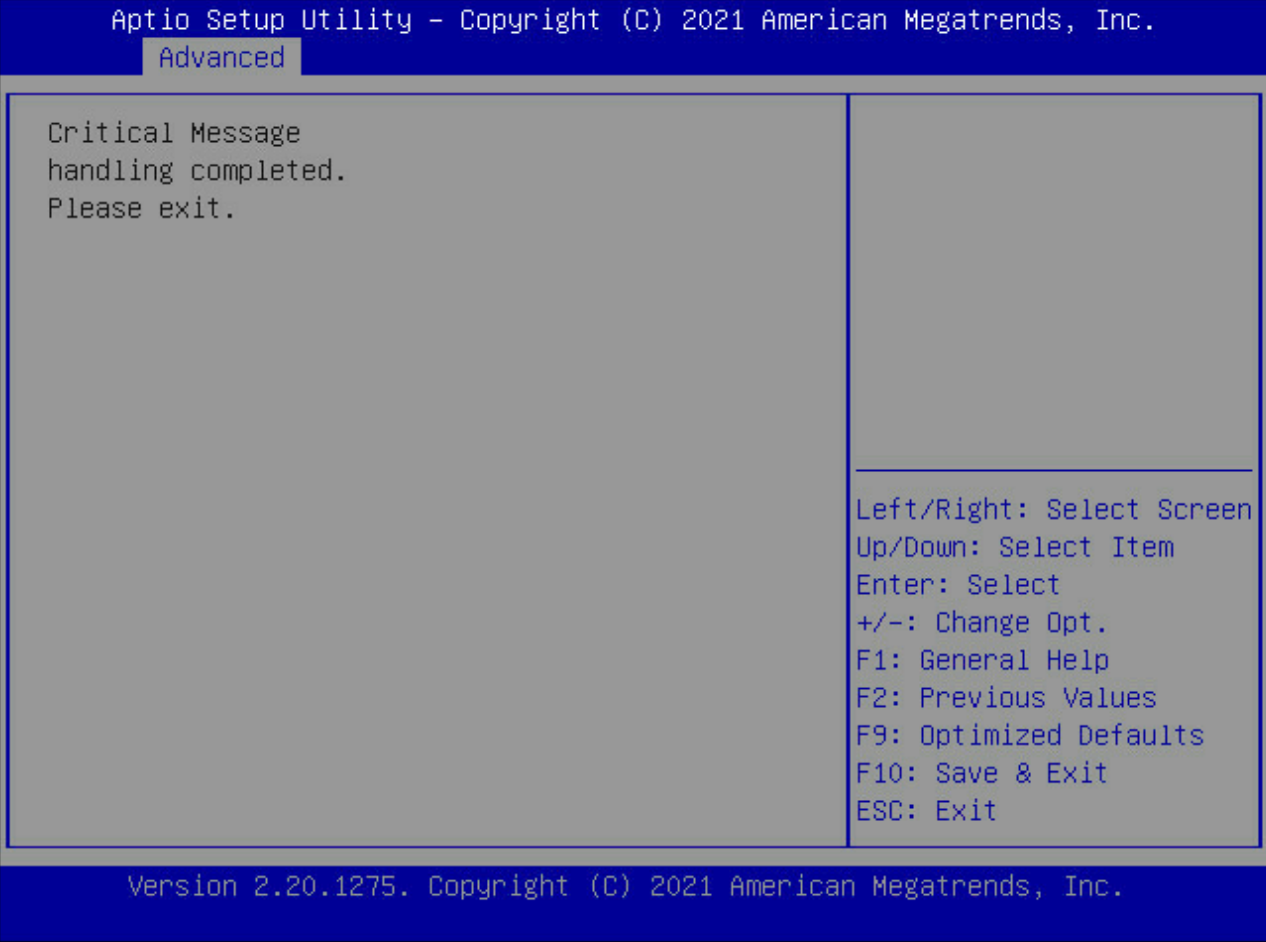
返回BIOS -Advanced界面,发现第二张raid卡已找到,正常显示。
移动光标至该Raid卡回车进Raid卡配置界面,进入”Configuration Management”页面,选择”Create Virtual Drive”,如下图:(如若此处无”Create Virtual Drive”选项请参照1.2.13)
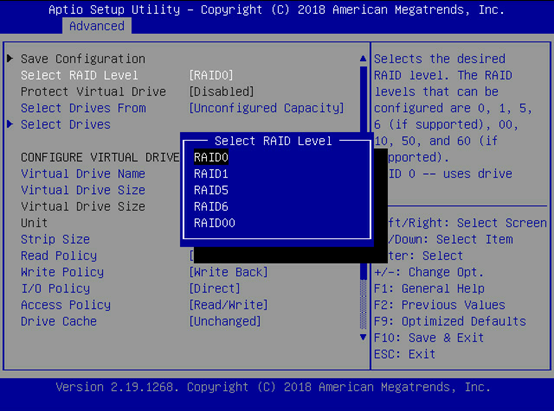
选择RAID0
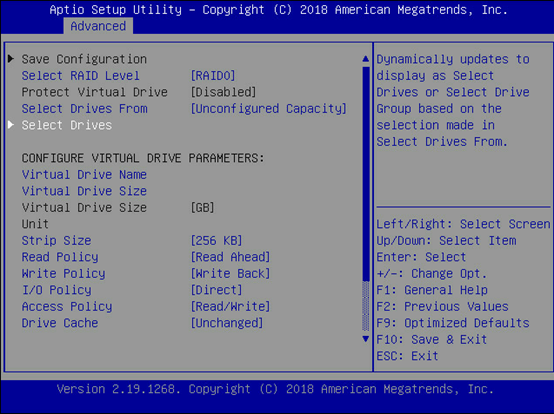
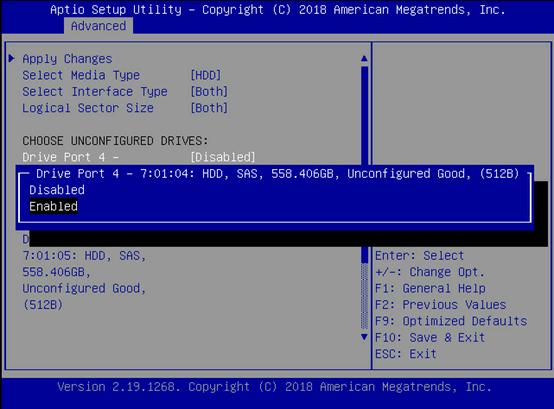
将光标定位在需要选择的硬盘上,选择enabled
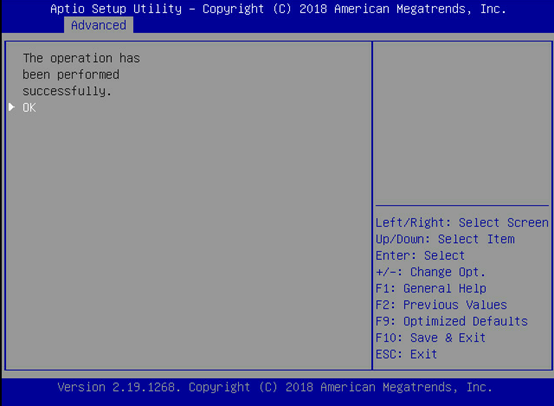
选择完成后,选择保存更改

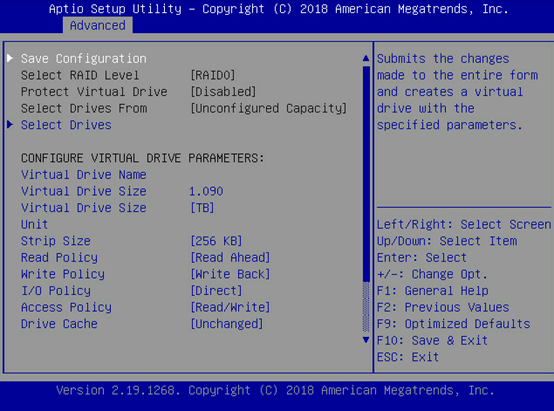
进入”Configuration Management”页面,没有”Create Virtual Drive”

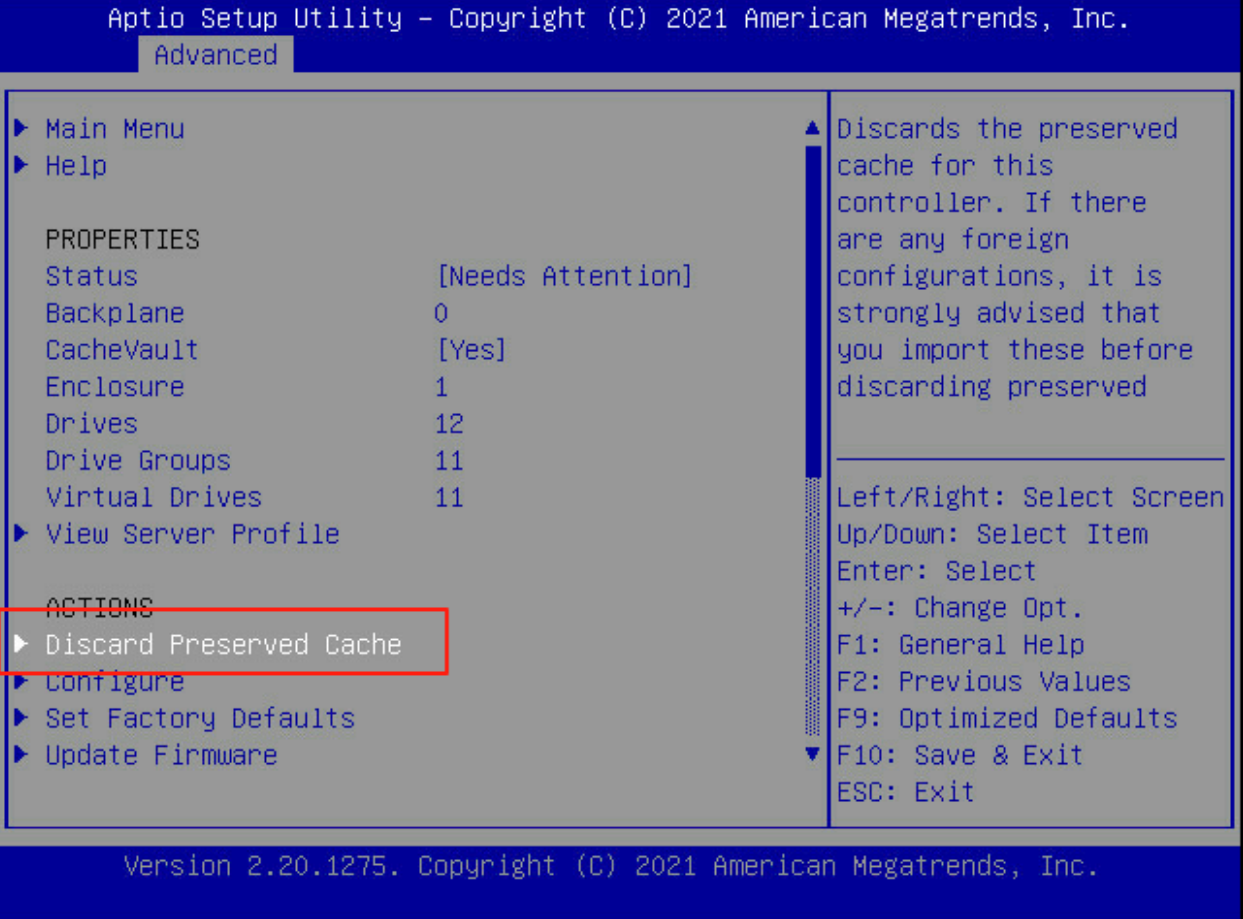
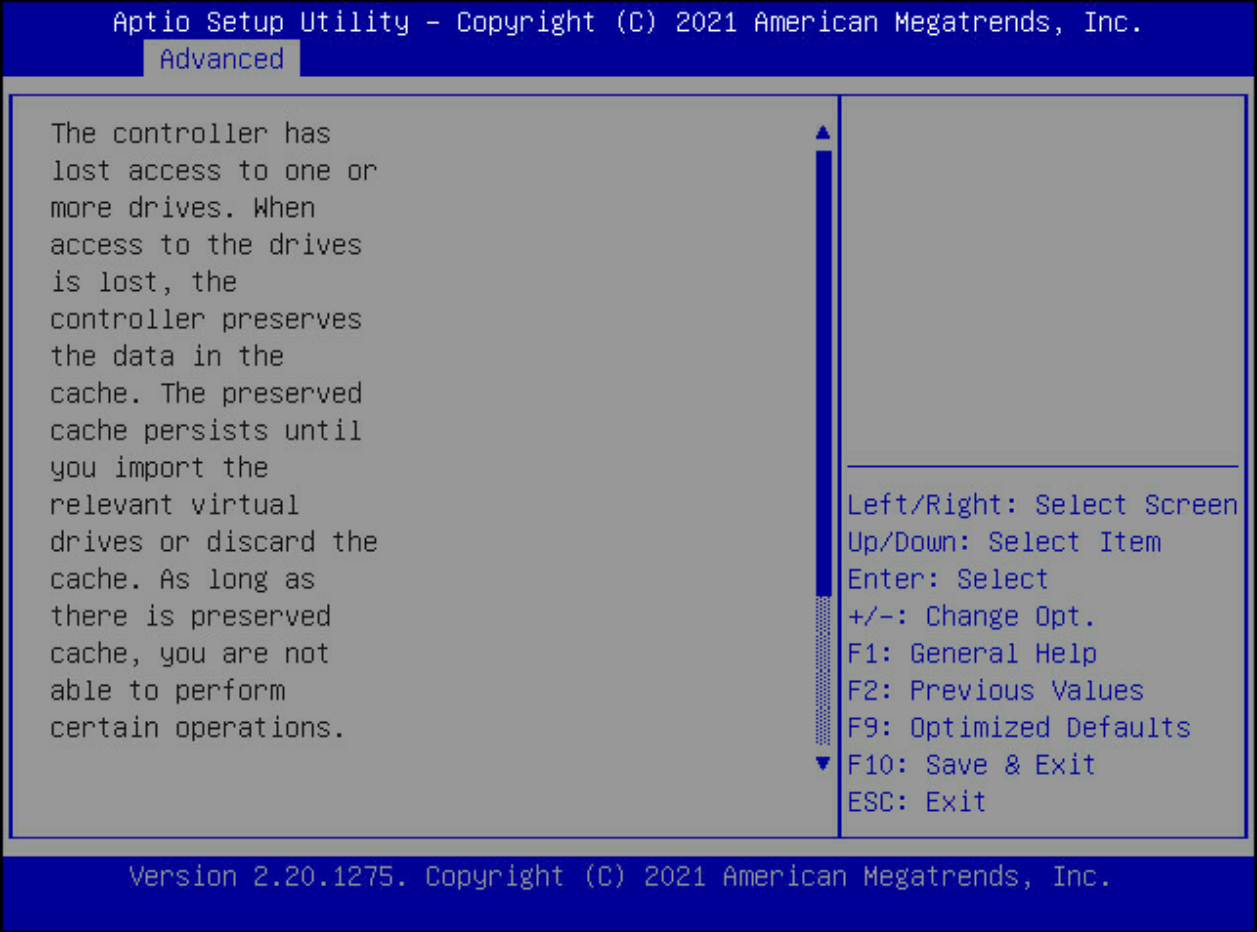
返回至如下界面,选择Discard Preserved Cache(丢弃保留的缓存)回车
更改disabled至enabled,选择yes回车。
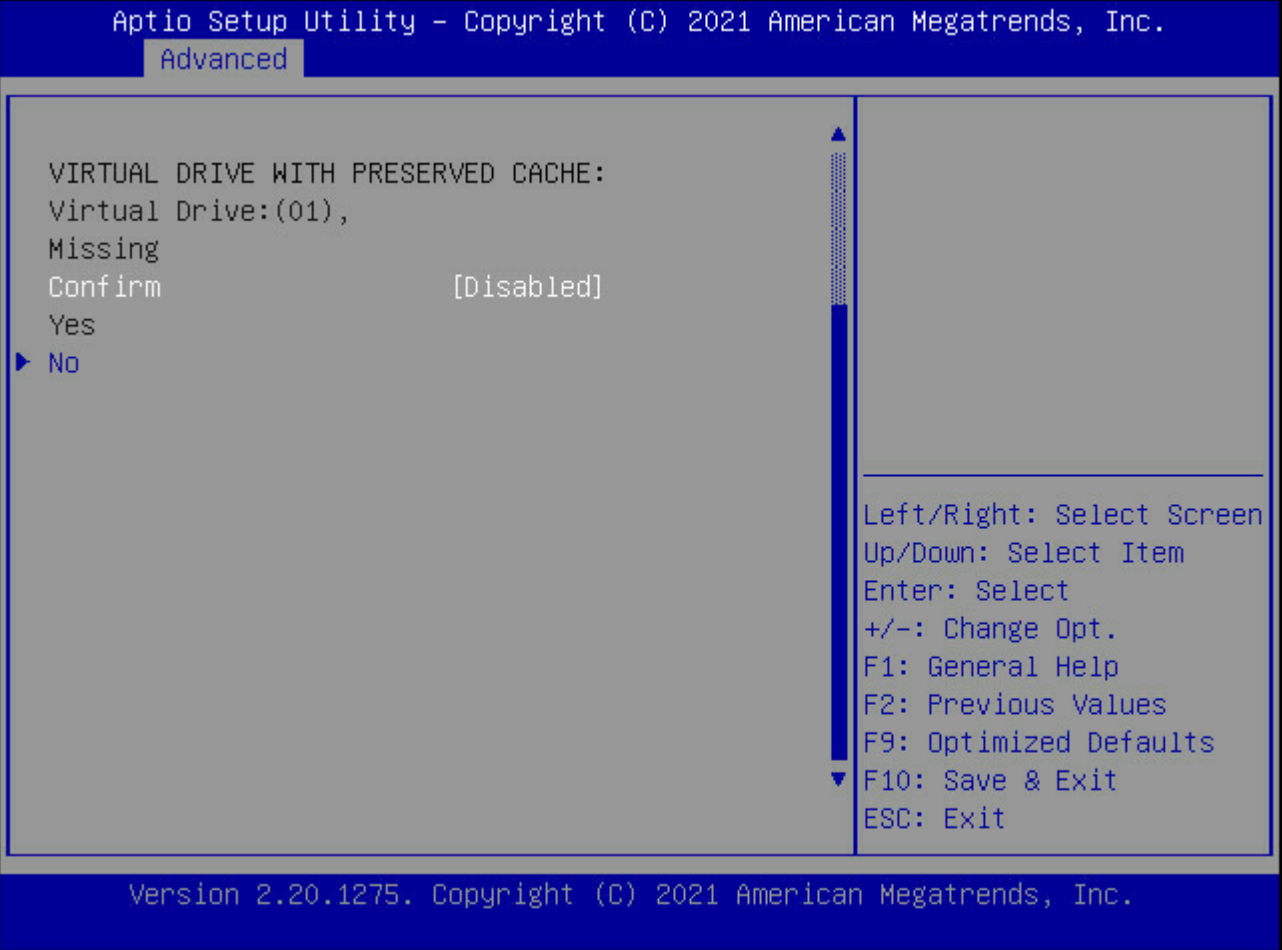
返回至Configuration Managerent回车,发现已经可以正常创建raid。
案例分享:与如上内容相关,浪潮服务器NF5466M5,服务器无法进入RAID卡配置,通用的Ctrl+R或Ctrl+H无效。
根据BIOS的启动设置有关:Advanced——》Boot Mode——》Legacy Mode,那么开机按CTRL+A,可以看到A、B、C、D……对应第一、第二、第三、第四……块硬盘。如果是第四块硬盘就选D,进去后可以看到状态为Fail,正常状态应该是Online,删除Raid0后重建就可以了。
如果是UEFI模式,可以在BIOS中Advanced设置RAID卡。
具体步骤双击如下附件文件:Ctrl+A快捷键阵列卡配置步骤(例如PM8222_PM8204)-浪潮信息.mhtml

相关案例:浪潮机器带外做raid0,不成功,重启主机后阵列卡正常。
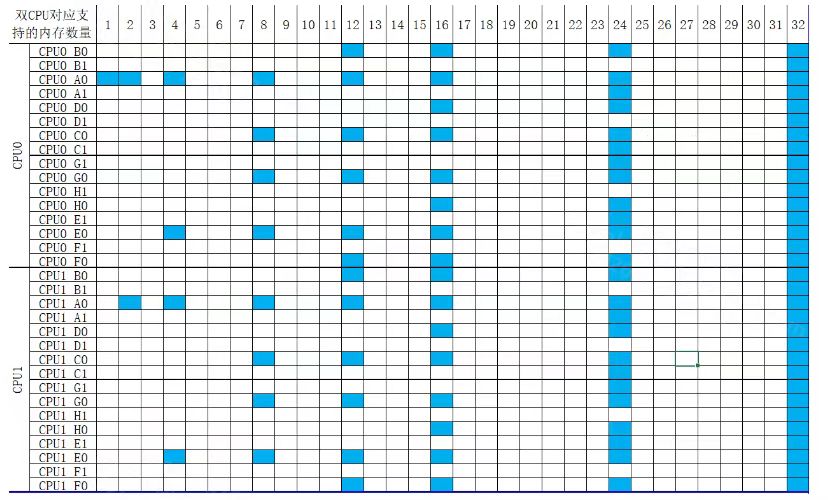
浪潮服务器内存插法:
案例分享:烽火服务器FitServer R2280 V6设备亮红灯,服务器运行正常,业务正常。只是带外有如下报错信息:
134 | 11/29/2023 | 00:07:14 | Voltage #0x4f | Lower Critical going low | Asserted
135 | 11/29/2023 | 00:07:14 | Voltage #0x4f | Lower Non-recoverable going low | Asserted
用户希望消除这些报错信息。
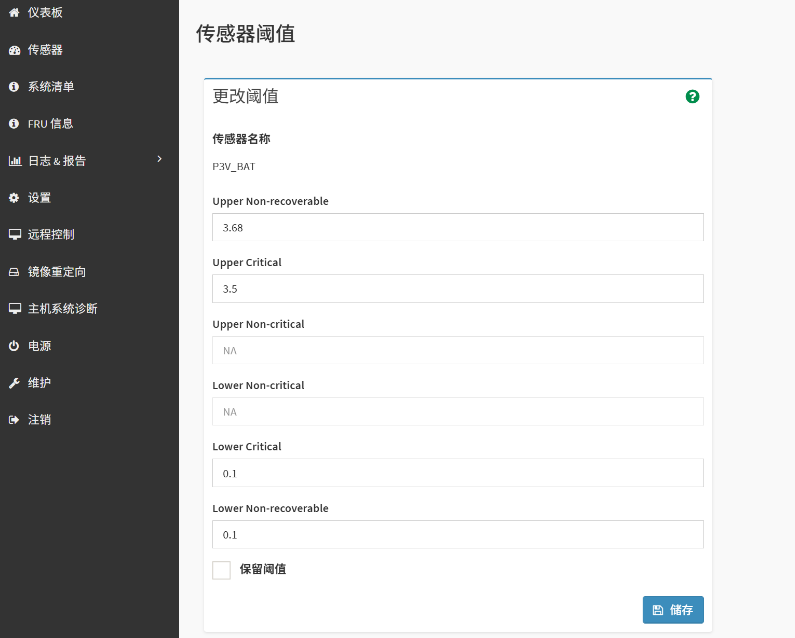
解决方法:点击报错的传感器图标——》点击“更改阈值”——》在阈值最后两项里填写0.1,勾选“保留阈值”,再点击“存储”确定后正常。如果无法解决,需要更换主板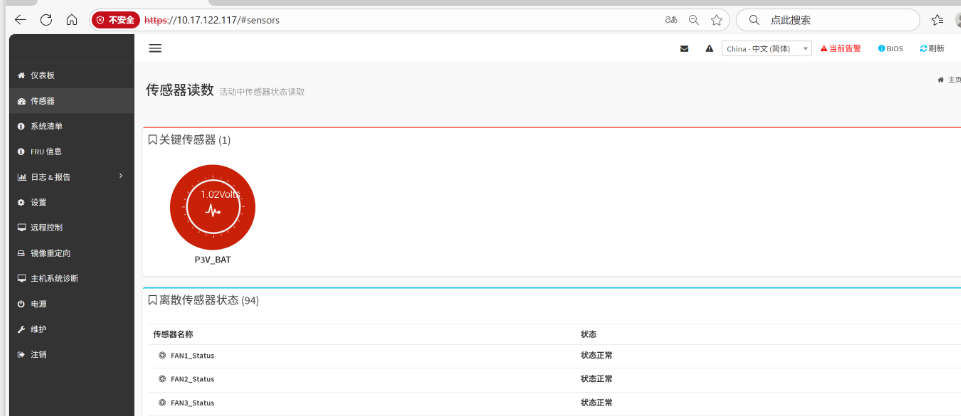
以上案列针对于未带coms电池,用户机房较远,暂时处理去除报警的情况。
案例分享:针对于曙光服务器,Linux下dmesg -T系统报错与主板上内存槽位的对应方法。
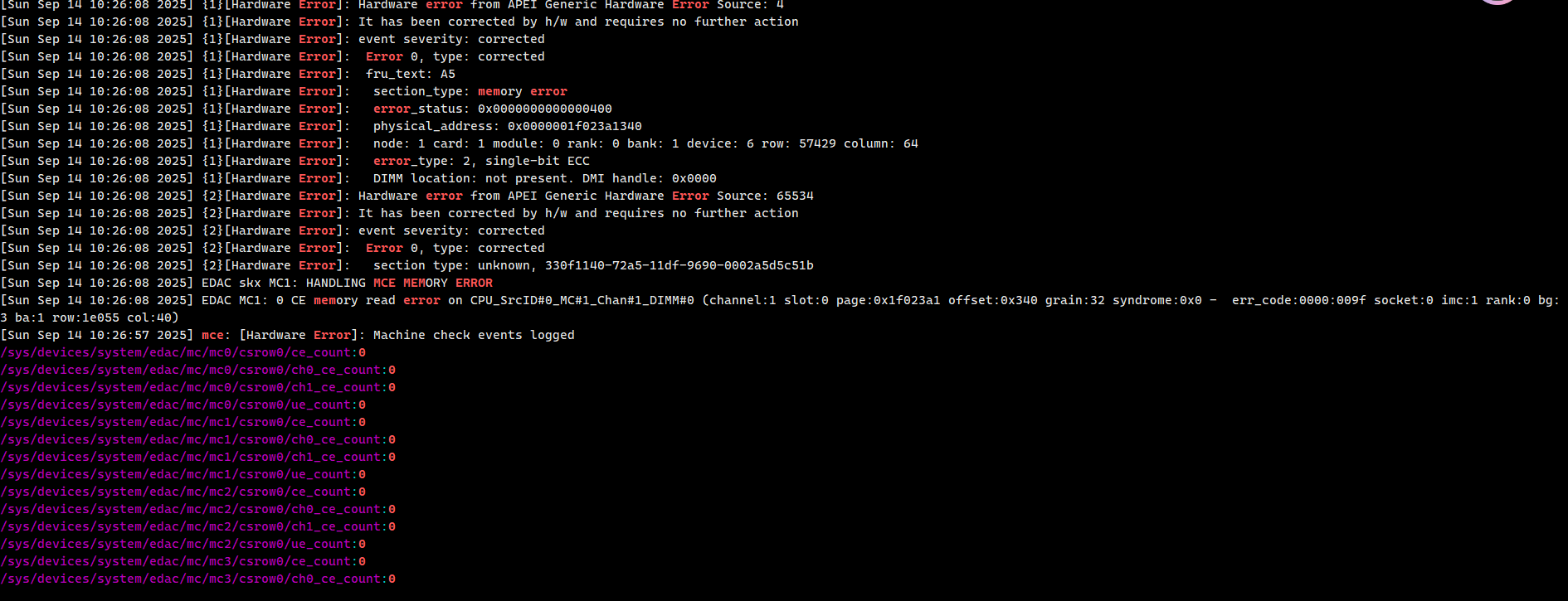
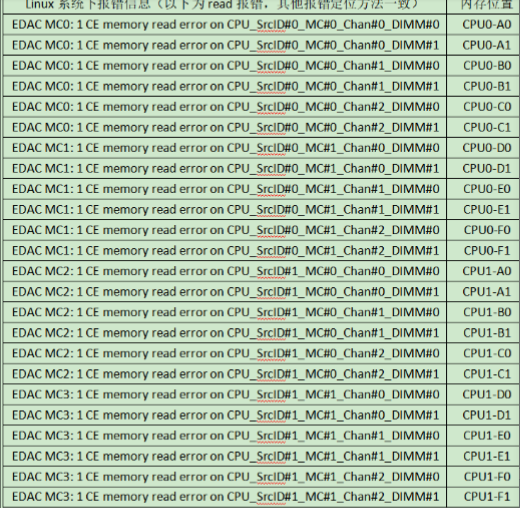
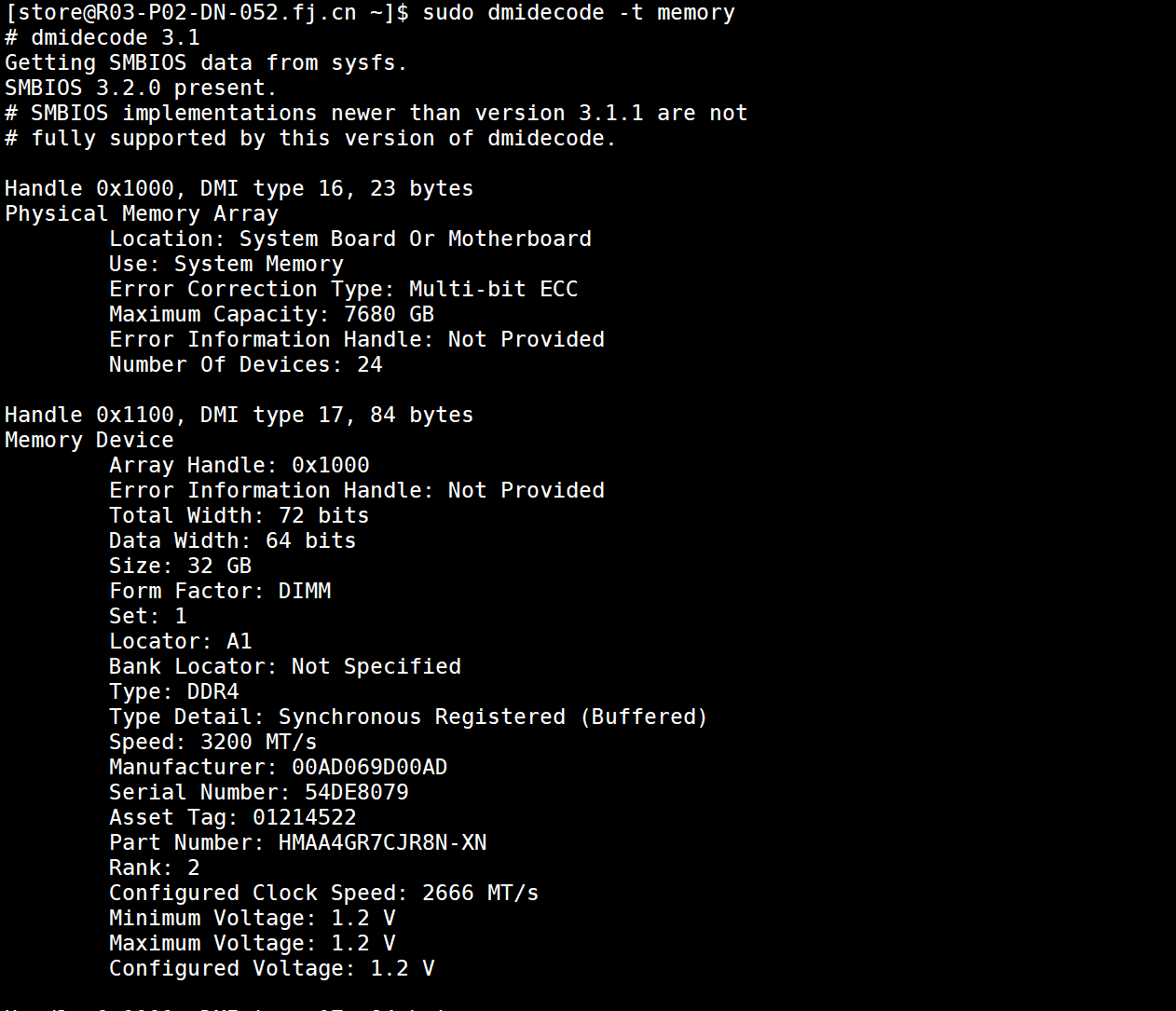
另外可以使用:sudo dmidecode -t memory,确定内存的SN。注意Locator的信息。
相关案例:曙光I620-G30内存频繁报CE服务器内存问题
曙光服务器频繁报内存CE,就是曙光bios对内存CE的阀值太低,需要至少232版本调高阀值,可以直接刷到235版本,同时如果之前已经换过这条现在报错的,就同步对调一下cpu,有时阀值调高了CE还是很频繁,导致还是超过阀值告警要更换的。
案例分享:针对于浪潮服务器,以NF8480M5 设备序列号:[已脱敏]为例,Linux下dmesg -T系统报错与主板上内存槽位的对应方法。如下图:CE memory read error on CPU_SrcID#2_MC#0_Chan#1_DIMM#0,定位为CPU2 C1D0
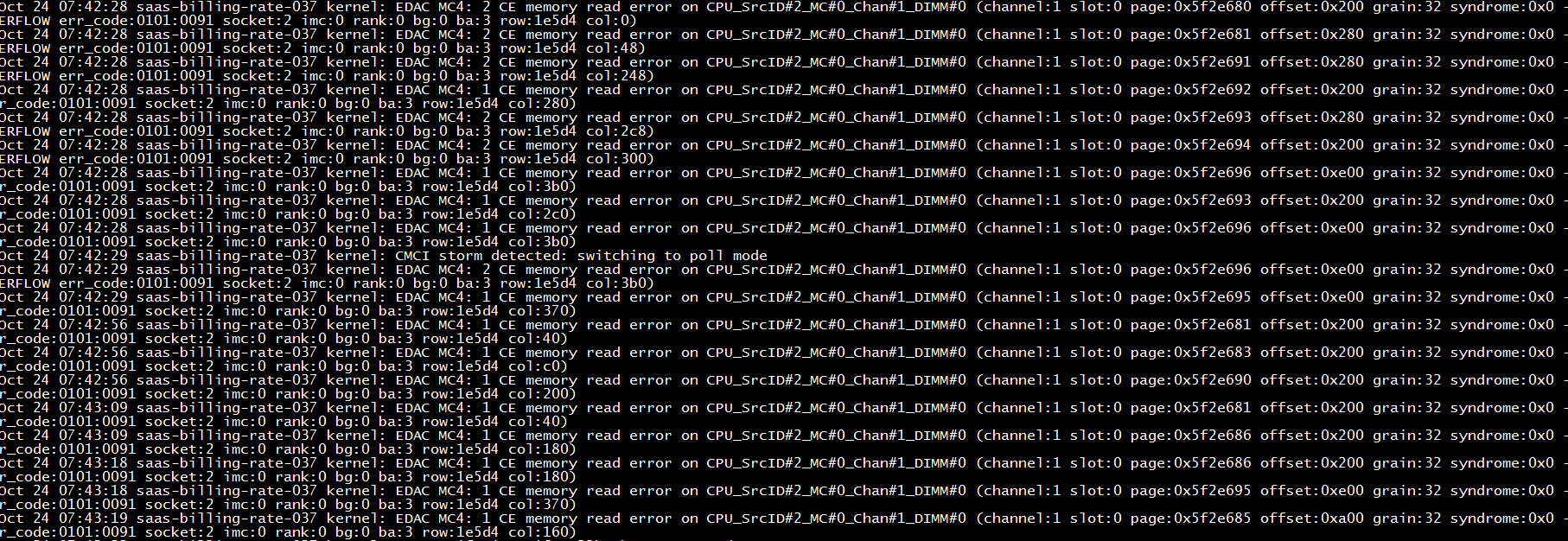
CPU2 C1D0位置对应主板插槽如下图,右下角红色箭头:
也可以通过:sudo dmidecode -t memory命令输出的Locator定位,如下memory.log为日志,注意Locator的信息。

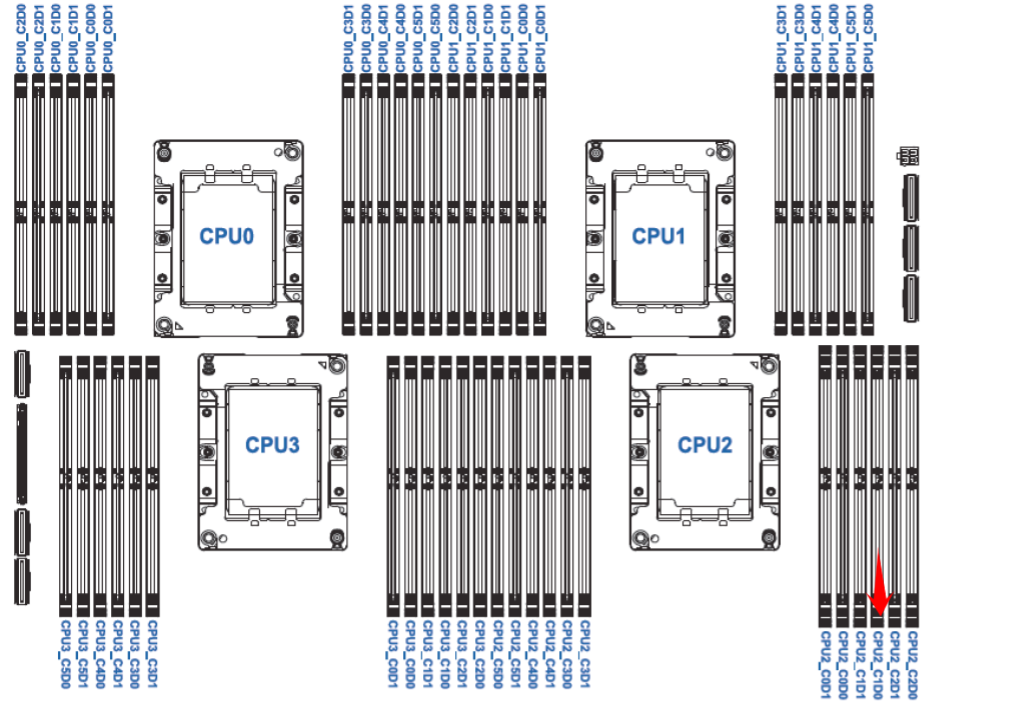

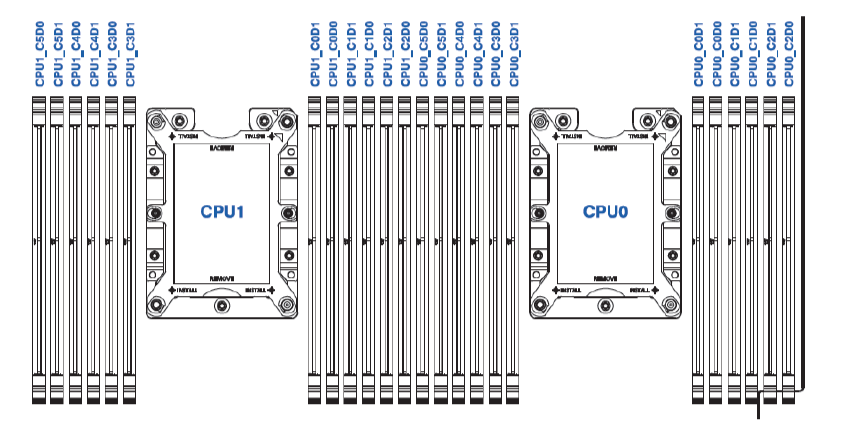
如下为浪潮服务器2路服务器通用的内存槽位图:
案例分享:DELL主板刷新SN的新方法:主板跳线
之前针对DELL服务器如果出现需要更换主板的情况,因为序列号只能更改一次,需要确认替换件主板的序列号为空,或者要求供应商发货的时候刷好服务器设备的SN。现在找到新方法,具体如下:
跳线接PWRD_EN 2、3引脚,由蓝色框示意的默认1、2引脚跳到红色框示意的2、3引脚,具体如下图


然后直接上电开机按F10,进入Lifecycel——》系统设置——》服务标签设置
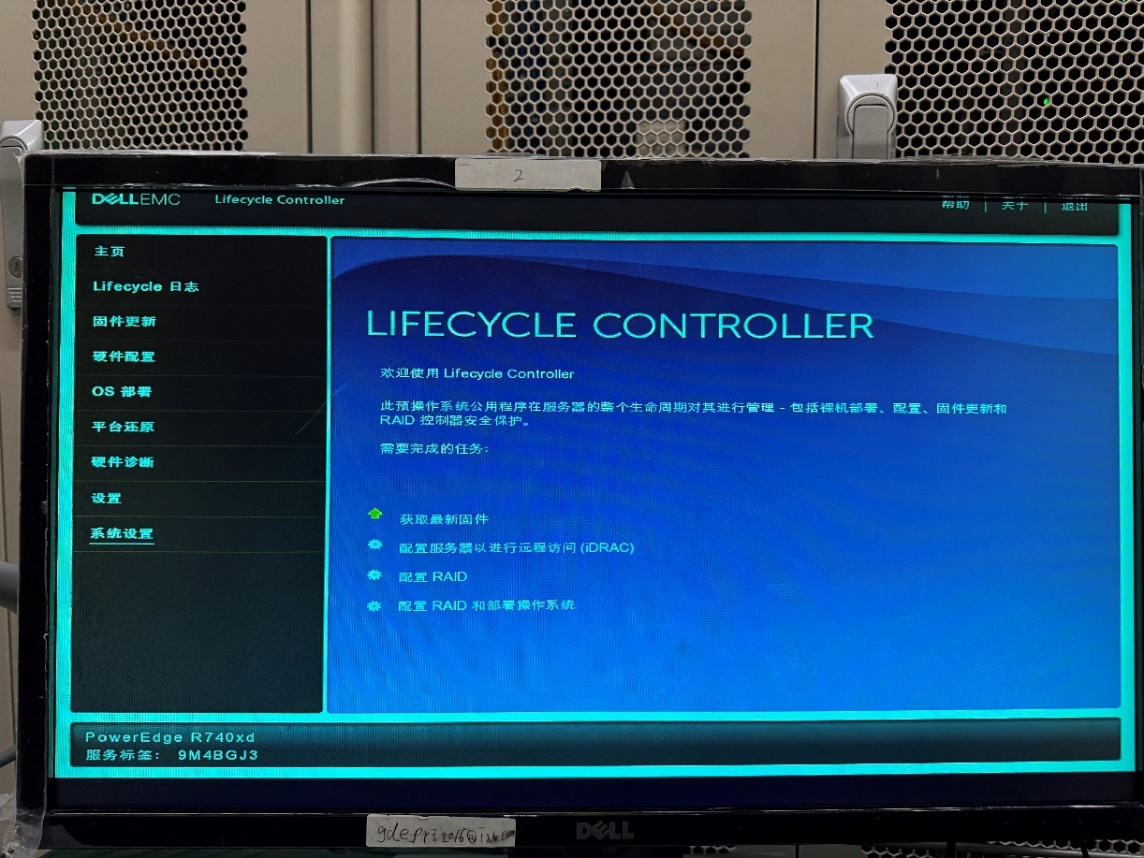
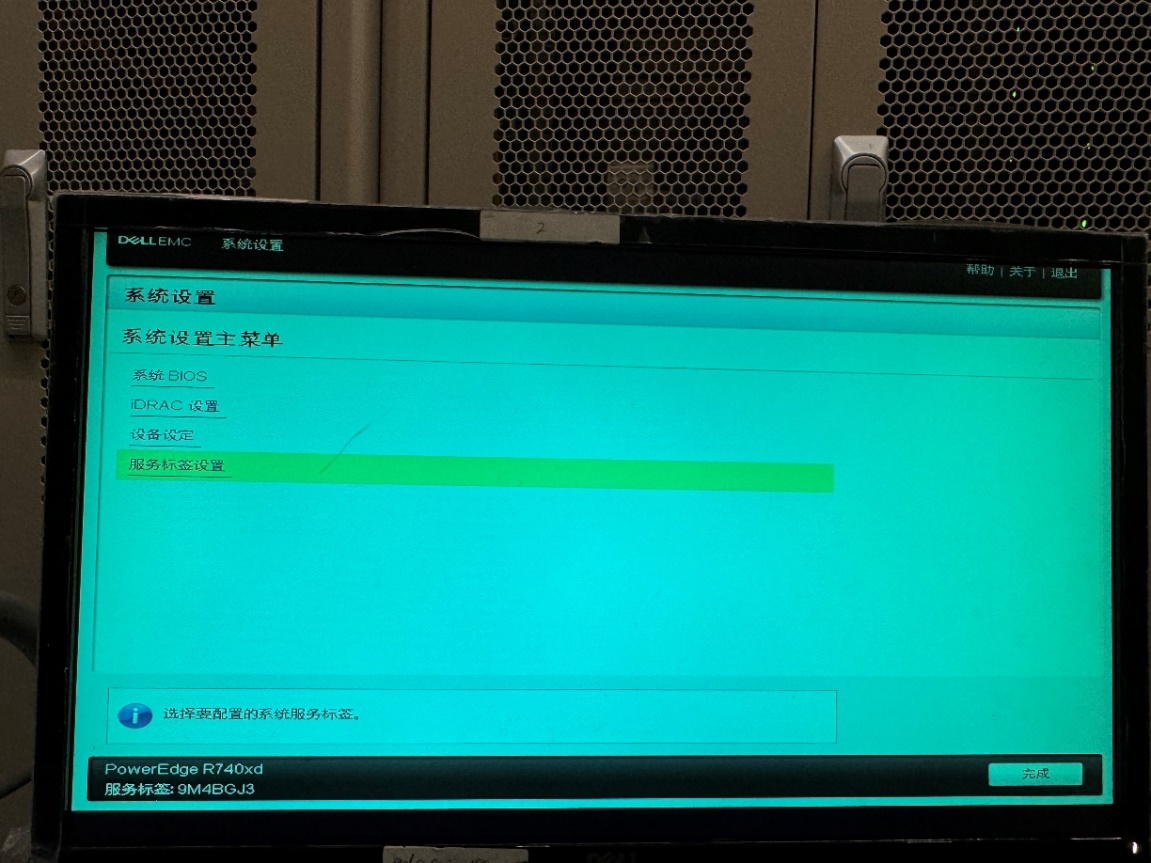
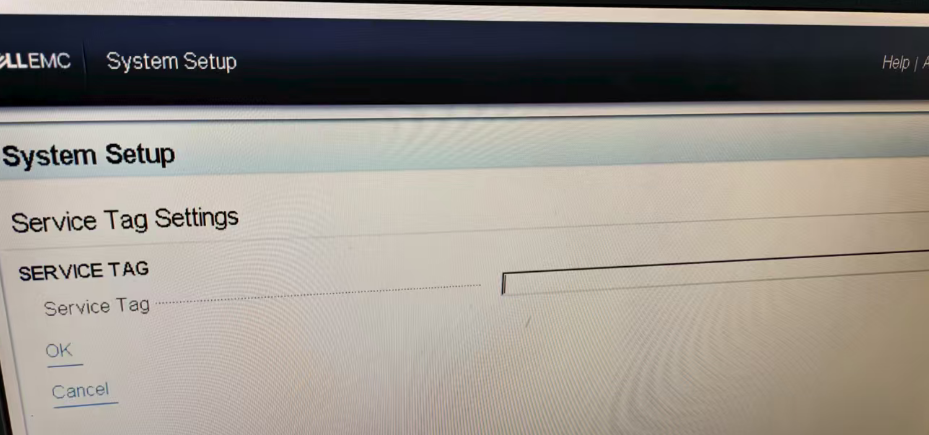
更改序列号完成后,关机恢复跳线至1、2引脚(否则更改的序列号无法保存)
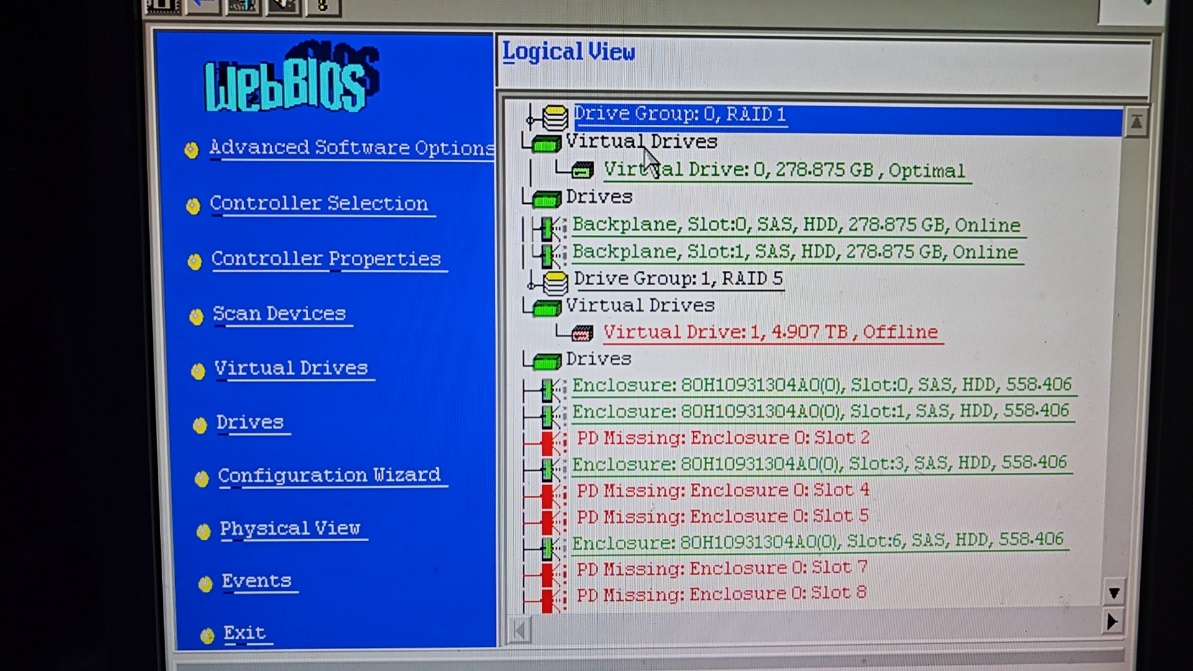
案例分享:设备厂家:曙光 I620-G10 设备序列号:[已脱敏]。这种主机时间已经比较长,配置raid的方法特殊。操作界面如下图,具体操作方法双击附件的文件:WebBIOS做RAID5配置方法.mhtml

案例分享:HP服务器更改SN
启动按F9键从 System Utilities 屏幕中,选择系统配置>BIOS/平台配置(RBSU)>高级选项>高级服务选项>序列号。
输入序列号,然后按 Enter。
保存设置。
分享处理思路:针对于CPU故障或内存故障,如果首次交换CPU或更换内存后故障复现,第二次维修避免盲目换件:使用杏雨梨云WinPE(已经连续使用十年),引导进入PE系统,工具进行CPU和内存测试。
HARDWARE_FAULT20250529094431414
设备序列号:[已脱敏]
设备型号:烽火 FitServer G4A60 V5
简要情况:
第一次保保修:日志报错提示Processor #0xff | IERR,5月24日两个cpu对调故障消失。5月29日收到二次报修单,没有提示具体哪个CPU故障。通过WinPE现场测试,内存测试3个小时未发现故障。CPU满负荷压测了20分钟,后面就卡住死机了。单颗CPU轮流测试,其中一颗启动到系统界面就卡住死机。确定其中一个CPU问题,型号为:Intel CLX-SP 6248R 24C 3.0GHz 35.75MB。更换后正常。
第二次保修:
日志报错07/11/2025 | 16:17:03 | Processor #0x02 | Throttled | Deasserted——》日志解读2 号处理器此前因温度/功耗触发了降频保护(Throttled),现已解除限制(Deasserted),恢复正常性能状态。因为此主机业务压力较大,并设置了CPU新能最大,用户强烈要求必须解决,后更换此CPU。更换下的CPU用到另外一个省份业务量较小的主机CNX2030093上此CPU正常使用。
案例分享:超聚变服务器带外不通,关机后出现不通电:
现在遇到超聚变RH2288H V5 / RH5288 V5带外不通,关机后主机不加电、电源灯闪烁的情况。
一句话说明:服务器运行的没有问题,带外不通,关机后启不来了,问题变大了。这个风险一定要跟客户同步一下,因为后续更换主板需要一个期限,这个期限用户无法使用。同步风险,避免用户不满。可以直接向客户说明:非常可能是超聚变设计的问题,不同省市都遇到了类似的情况。
超聚变硬盘故障更换后提示:轻微告警
解决方法1:拔下后重启带外,再插入硬盘后正常
解决方法2:在阵列卡配置中清除缓存数据(注意用户数据)
带外管理相关命令(没有完全事件):
# 重启BMC(注意:这不会重启服务器,而是重启BMC控制器)
sudo ipmitool -I lanplus -H [内网IP] -U admin -P password mc reset cold
# 查看BMC信息
sudo ipmitool -I lanplus -H [内网IP] -U admin -P password mc info
# 正确重启服务器的命令(注意这是重启服务器,严格区分)
sudo ipmitool -I lanplus -H <BMC_IP> -U <用户名> -P <密码> chassis power reset
sudo ipmitool -I lanplus -H [内网IP] -U admin -P password chassis power reset
sudo ipmitool -I lanplus -H [内网IP] -U admin -P password chassis power status
sudo ipmitool -I lanplus -H [内网IP] -U admin -P password chassis power on
sudo ipmitool -I lanplus -H [内网IP] -U admin -P password chassis power off
#检查BMC IP配置
sudo ipmitool lan print 1
# 配置BMC静态IP
sudo ipmitool lan set 1 ipsrc static
sudo ipmitool lan set 1 ipaddr [内网IP]
sudo ipmitool lan set 1 netmask 255.255.255.0
sudo ipmitool lan set 1 defgw ipaddr [内网IP]
ipmitool raw 0x32 0x66 #恢复默认值
ipmitool lan set 1 ipsrc static (设置ipmi ip非DHCP)
ipmitool lan set 1 ipaddr [内网IP](设置IPMI 地址)
ipmitool lan set 1 netmask 255.255.255.0 (设置ipmi 子网掩码)
ipmitool lan set 1 defgw ipaddr [内网IP] (设置ipmi 网关)
ipmitool user list (列出ipmi 用户)
ipmitool user enable/disable <user id> (启用/禁用用户)
ipmitool user set password 1 default_pwd (修改ipmi 用户名1的密码)#root 修改后默认密码default_pwd
ipmitool user set password 2 default_pwd (修改ipmi 用户名2的密码)#admin 修改后默认密码default_pwd
ipmitool lan print (查看现在ipmi地址)
ipmitool mc reset cold (重启本地BMC)
案例分享:重启带外方法汇总(重启时服务器风扇声音会变大)
浪潮服务器特殊,浪潮NF5280M5、NF8480M5、NF5466M、所有浪潮M4机型,重启BMC有一个内嵌的按钮:BMC_RST,在服务器背面。M5机型UID等长按是服务器重启,后续M6以后的机型才是长按UID重启BMC;
HP、H3C长按UID按钮、曙光ID按钮、DELL按波浪形的蓝色灯;
BIOS中重置带外(免关机但会清除IP地址);
关机断电断网放静电(超聚变特别注意)。
浪潮NF5280M5
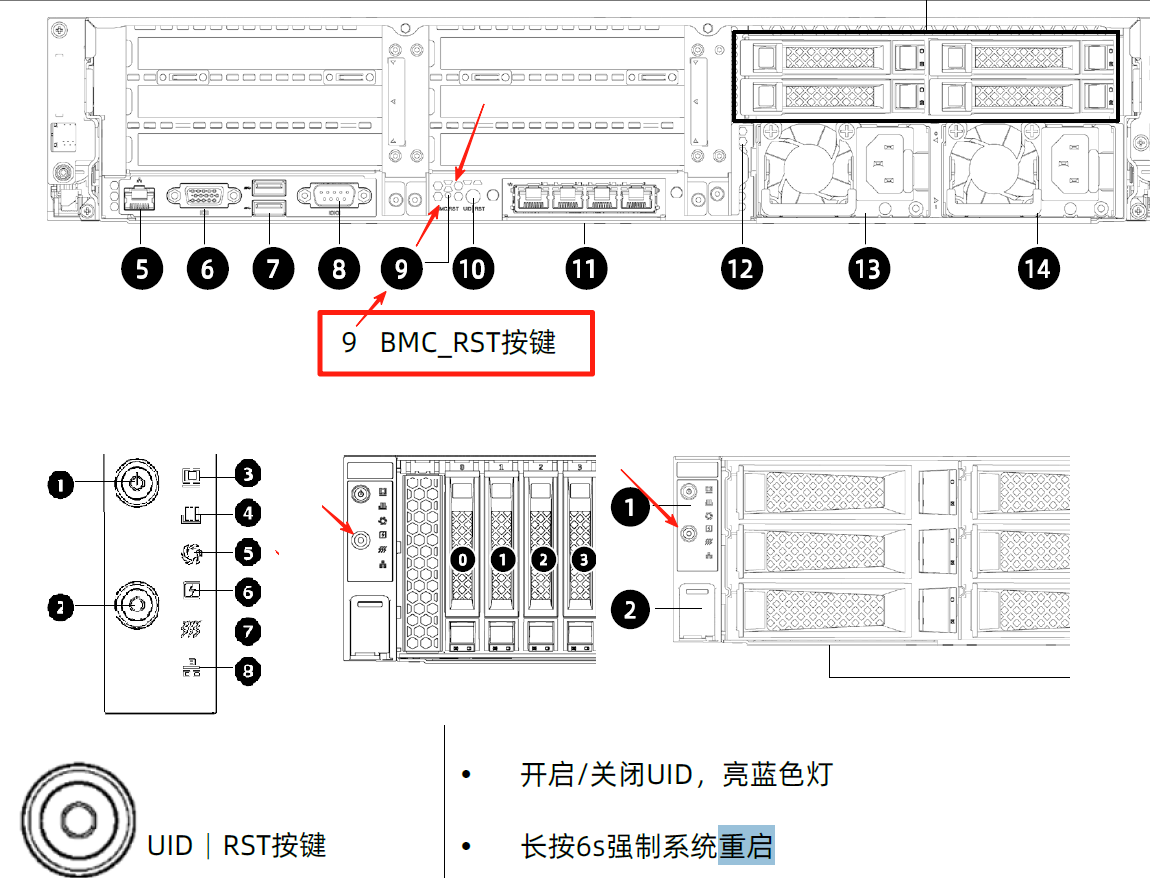
浪潮NF8480M5
浪潮NF5466M5

浪潮NF5270M4

案例分享:Dell更换Bios电池后无法开机或更换主板后,卡在POST界面或无法通电
问题处理思路:最小化系统测试:
卡在POST界面:针对于卡在POST界面,只插一根内存最小化系统测试,后启动正常,把内存重新插满后恢复正常。
无法通电:拔下LOM网卡后,服务器可以正常通电了,基本确定LOM网卡问题。(更新标准为OCP NIC 3.0厂商开始互相兼容)
相关案例:最小化测试尽量拔下所有备件,HP服务器背板导致加电无自检。
如下图为具体的故障提示:Server Critical Fault (Service Information: Power On Fault, System Board, AUX/Main EFUSE
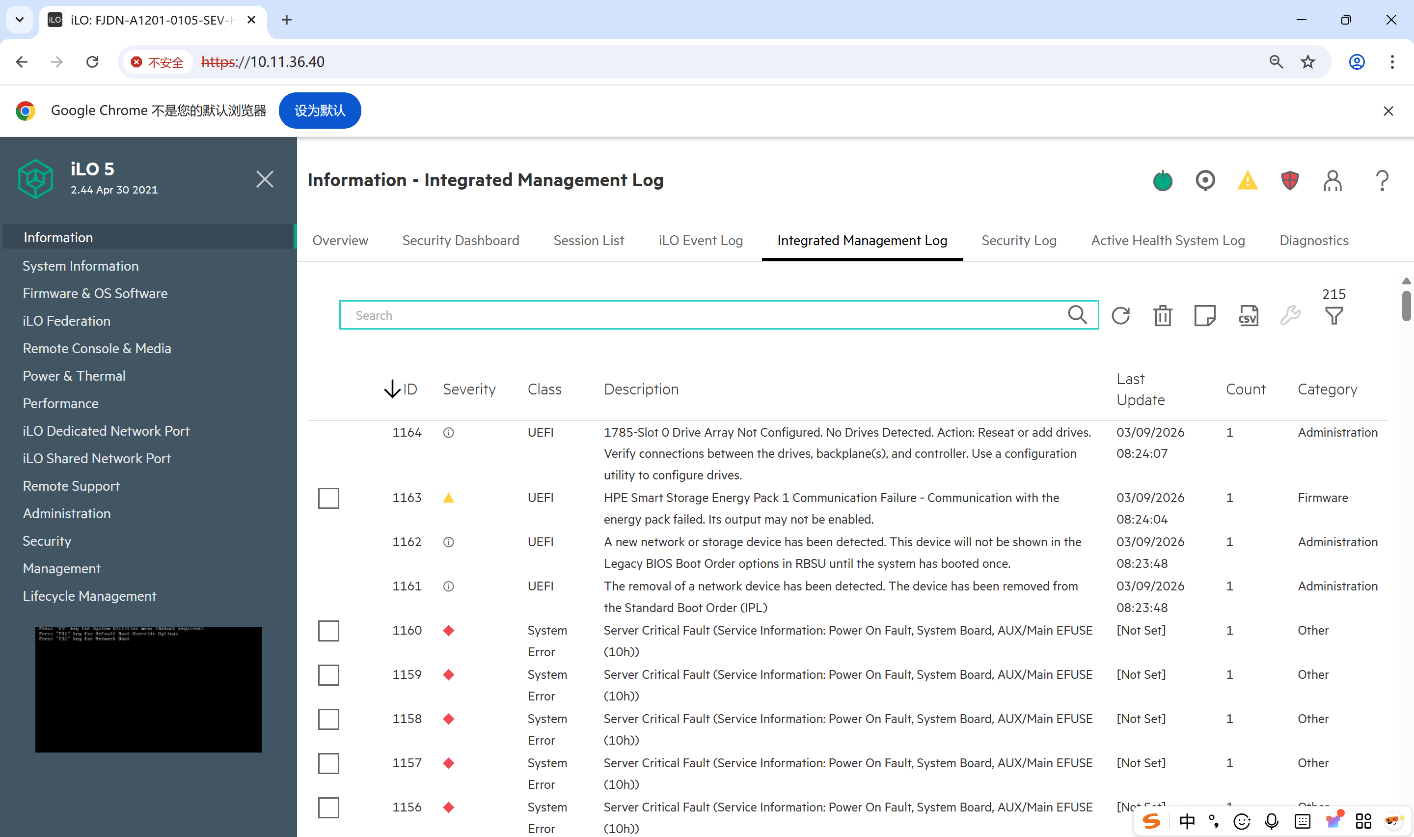
更换主板后,前面板灯交替闪烁如下图:

实际故障件:前面板硬盘背板


案例分享:设备序列号:[已脱敏] 设备厂家:DELL 设备型号:PowerEdge R740报错iDRAC:2025-05-26 01:41:24 CPU 2 VCCIO PG voltage is outside of range.
给的建议:关机、断电、断网放静电,最好CPU互换一下,iDRAC里cpu状态是正常的、电源状态也是正常的。后续如果再保修,考虑更换主板。
后续处理结果:对调CPU后,无法启动了,CPU插槽针脚弯了,后更换主板,后续针对voltage电压的问题,考虑只放静电。因为很可能只是传感器的误报。
经验分享:初步方案稳妥,第二次方案更加彻底(逐步加药量)
DELL R740xd
设备序列号:[已脱敏]
带外提示:The system board Pfault fail-safe voltage is outside of range.
解决方法:更换板载可拆卸网卡解决,河南已经有两个例子。之前另外一台主机6SZ9Y23更换2次主板未解决,最小化测试后发现网卡拆下后正常,最终更换网卡解决。
通过三次相同故障的处理,已经确定此故障,是更换网卡解决。物料号:NWMNX
需要验证:
设备序列号:[已脱敏]
2个光口2个电口物料号:6VDPG

网卡命名:
持续观察:
HARDWARE_FAULT20250619090124191
2102313EBX6TLA000108
eno3的定义:
eno3 是一个物理网络接口卡(NIC) 的标准命名,通常表示服务器上的一个独立物理网卡(例如以太网接口)。23
在Linux系统中,网卡名称遵循特定规则:
en 表示以太网(Ethernet)。
o 表示板载(on-board)设备。
3 是接口序号(如第一块网卡为 eno1,第二块为 eno2)。
HARDWARE_FAULT20260227110818645
8Y19TC3
ens7f1np1"遵循了"Predictable Network Interface Names"(可预测网络接口名称)规则,我来为您解释这个命名的含义以及它对应的是哪个物理网卡:
命名解析
en:表示以太网(Ethernet)
s:表示PCIe设备(Standard)
7:表示PCIe总线号(7)
f1:表示功能号(Function 1)
np1:表示网络端口(Network Port 1)
所以"ens7f1np1"表示在PCIe总线7上,功能1的网络端口1。
更换不同型号配件,持续观察:
更换的不同位数的内存,2R*8换2R*4,可以持续观察一下。
案例一:2102313EBXP0L9000615
DIMM110===Critical===uncorrectable error=== SN:[已脱敏]===32G===DDR4===2R*8
案例二:820972864

设备厂家:超聚变 5288 V5
设备序列号:[已脱敏]
2025年6月19日更换固态硬盘,已经通电30000小时
HARDWARE_FAULT20250509155422684
CN70300JR5
HP更换其他型号的SAS盘


HARDWARE_FAULT20250707155623623
CN790803X6
EG001200JWJNK===1.2T===SAS
HP更换其他型号的SAS盘

如果更换主板,请将设备sn刷成和原来一致,并创建以下4个账号提示:请工程师按照以下规则配置维修后的带外临时账号/密码信息:注:部分密码有更新
ID2:Administrator/7r4G0G7Y@XnKpQ 权限:管理员
ID4:ydadmin/@qNGZuuYpy1t3L 权限:管理员
ID6:ydview/creMydp@ph2023 权限:只读
ID7:AutoDevOps/LcAC4fTY17@LPJ 权限:管理员
案例分享:Dell服务器更换硬盘后无法创建RAID,清RAID卡缓存。具体错误提示为:待处理操作不成功。控制器上存在保留的高速缓存,因此无法完成操作。如下图:
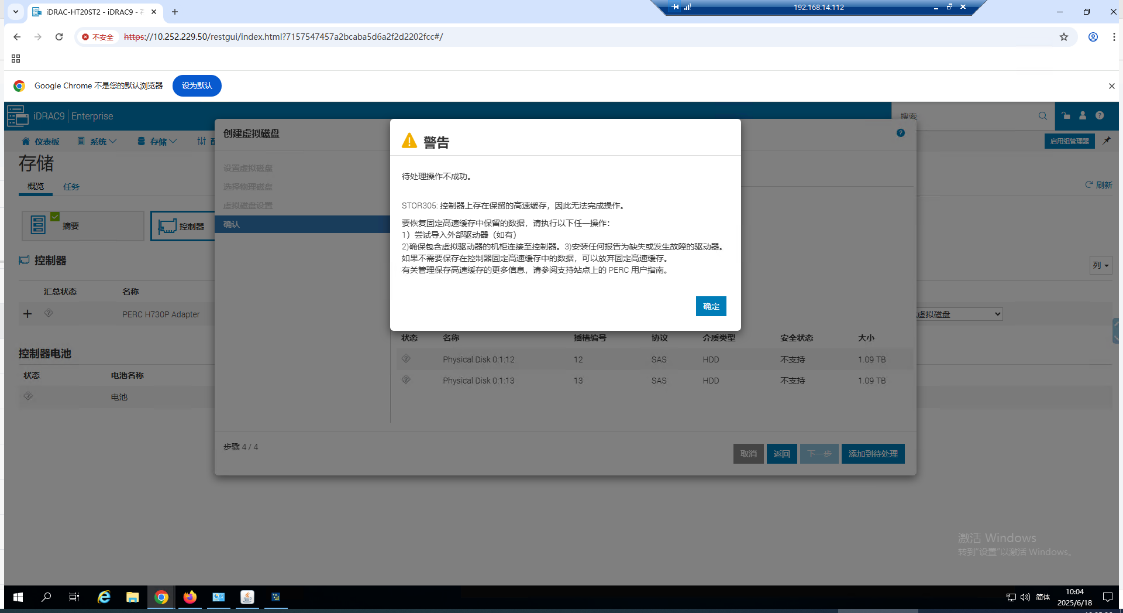
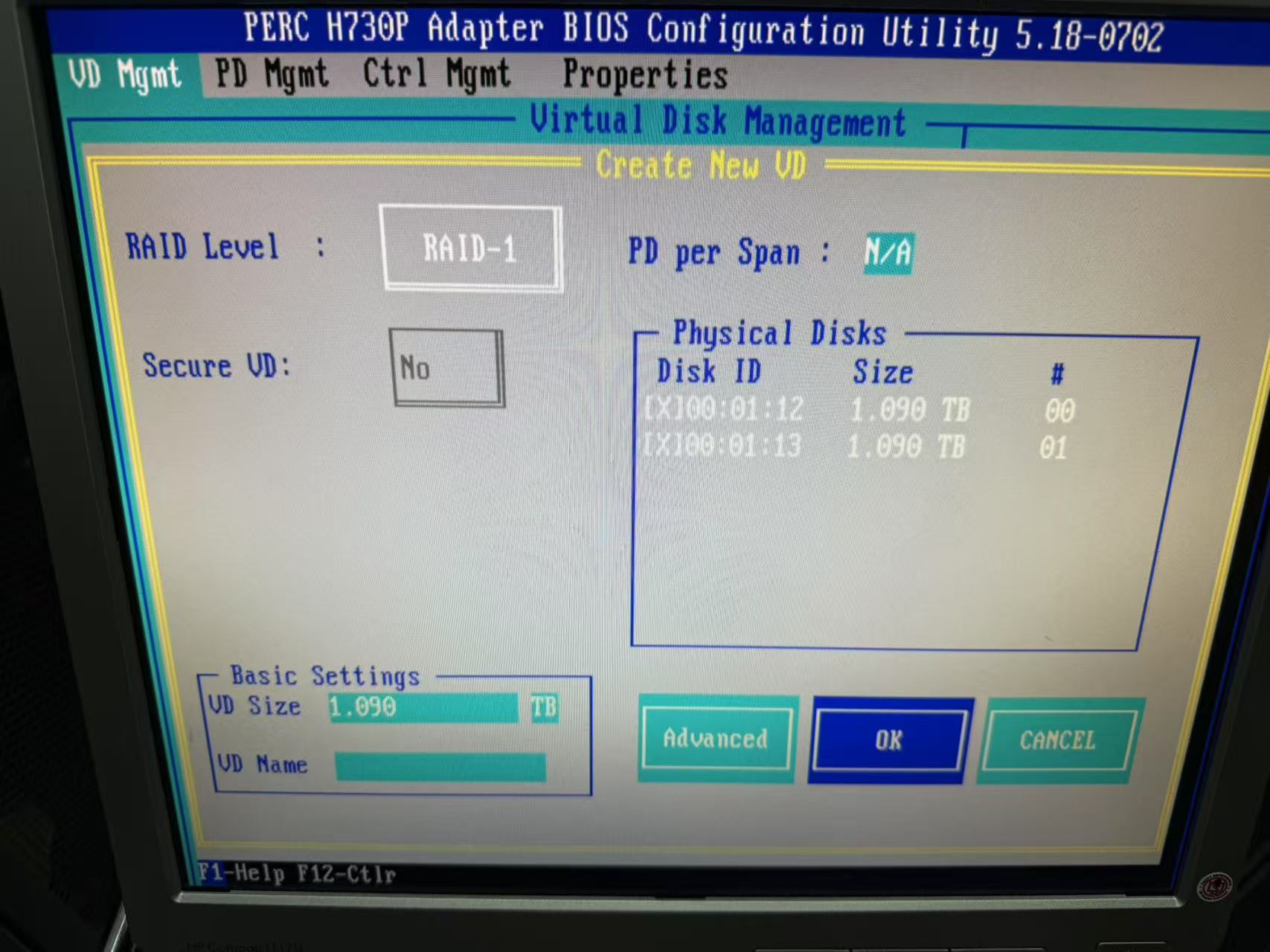
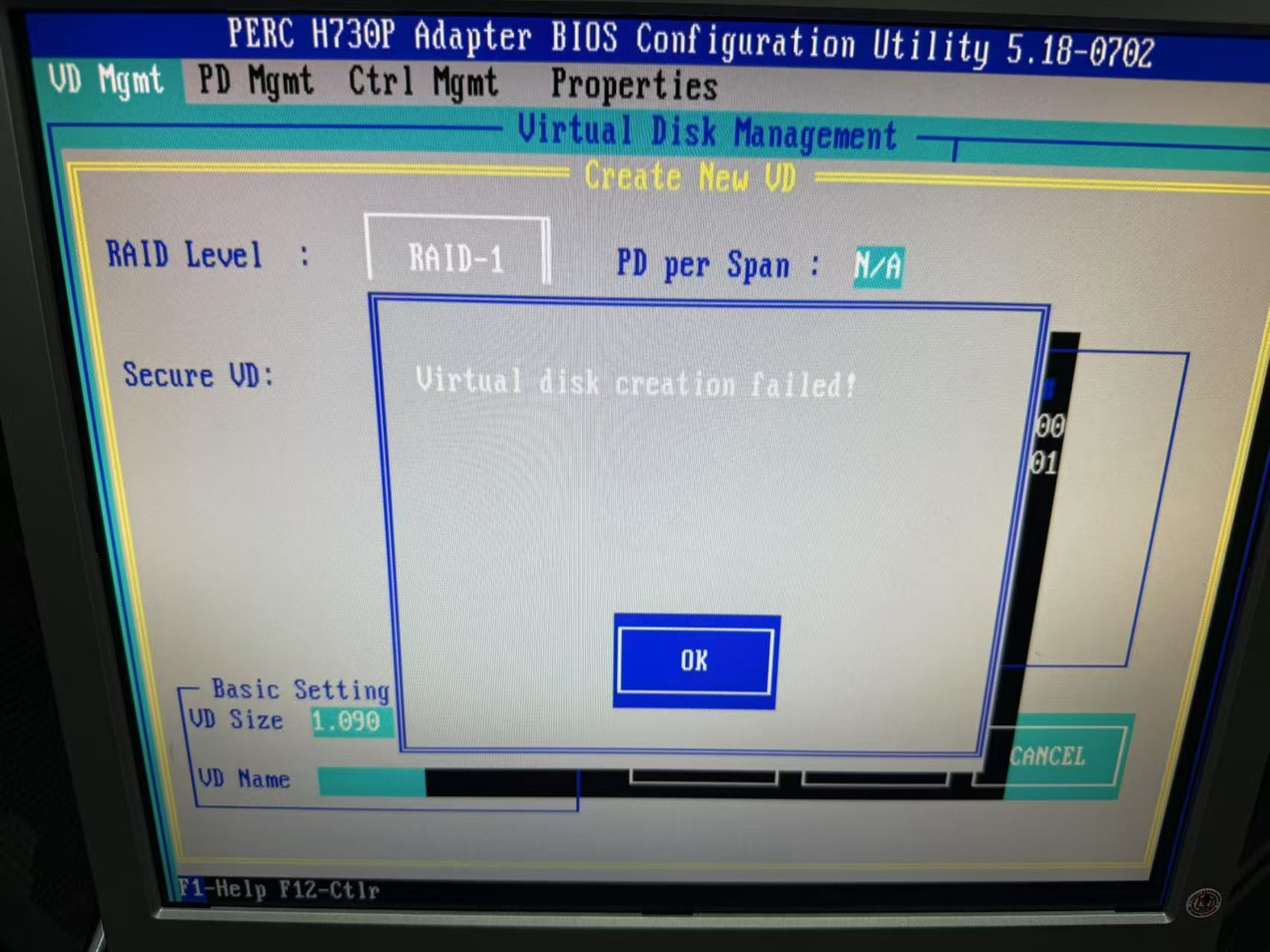
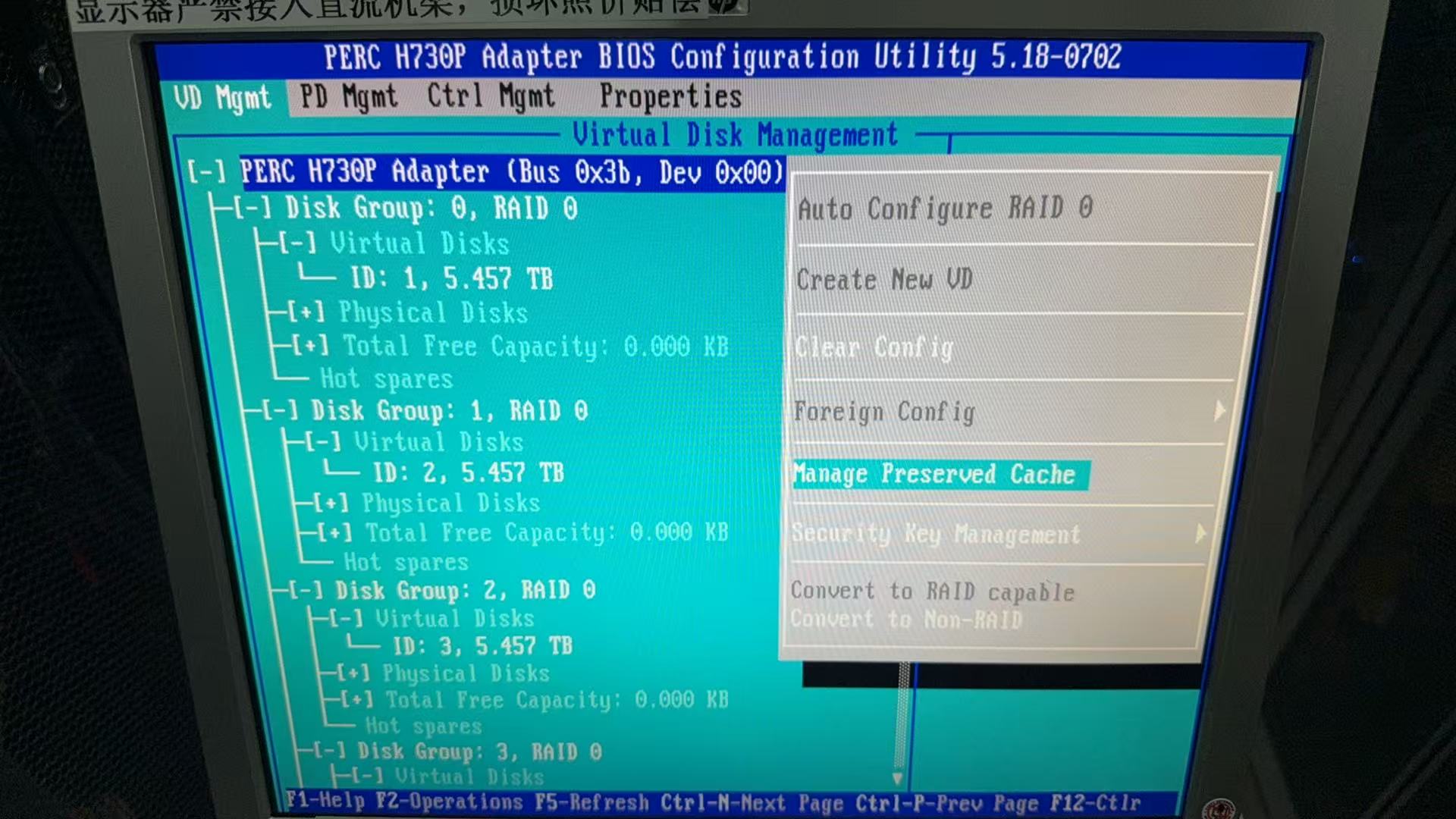
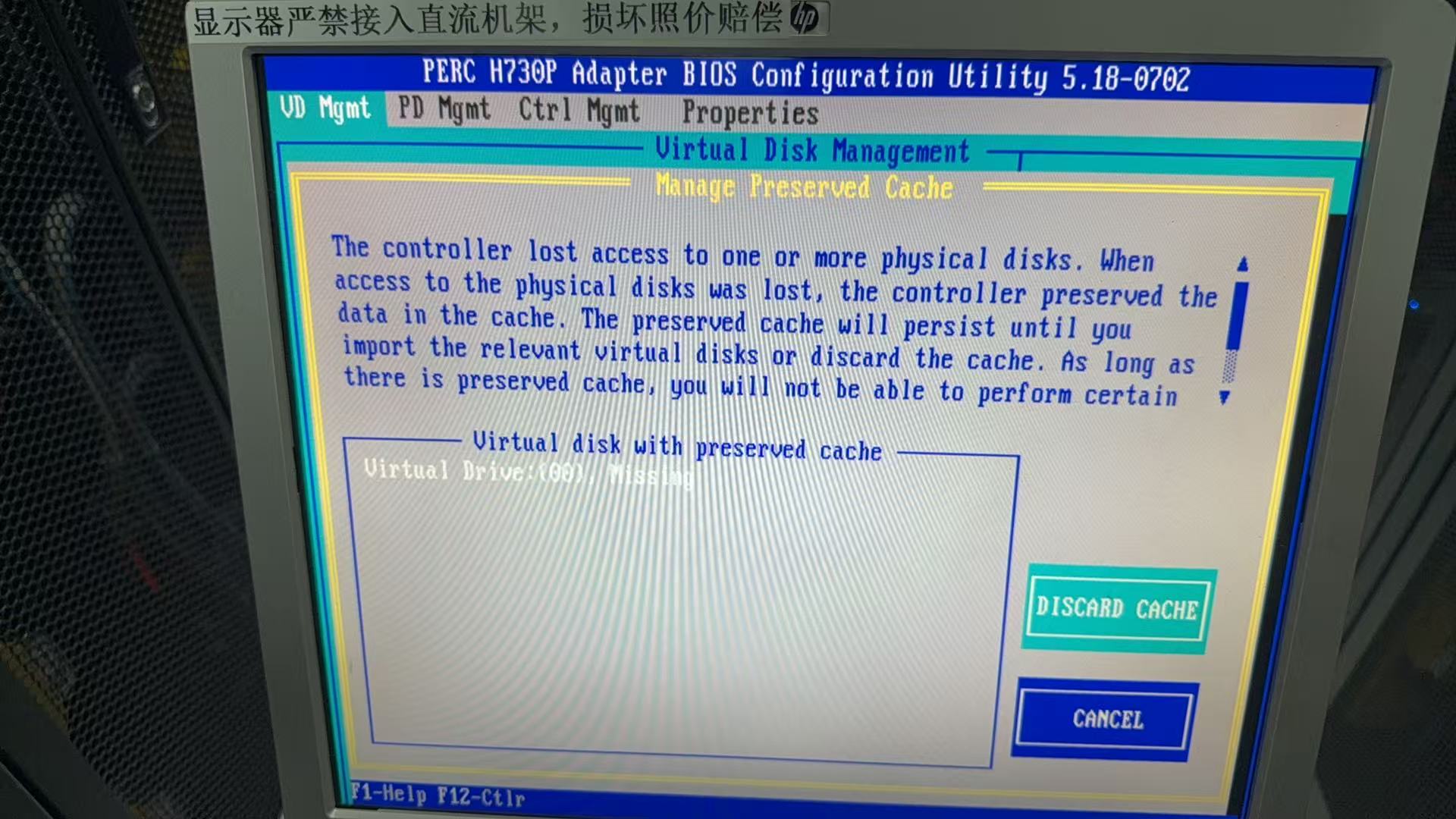
之前之后状态对比图
之前之后状态对比图
案例分享:
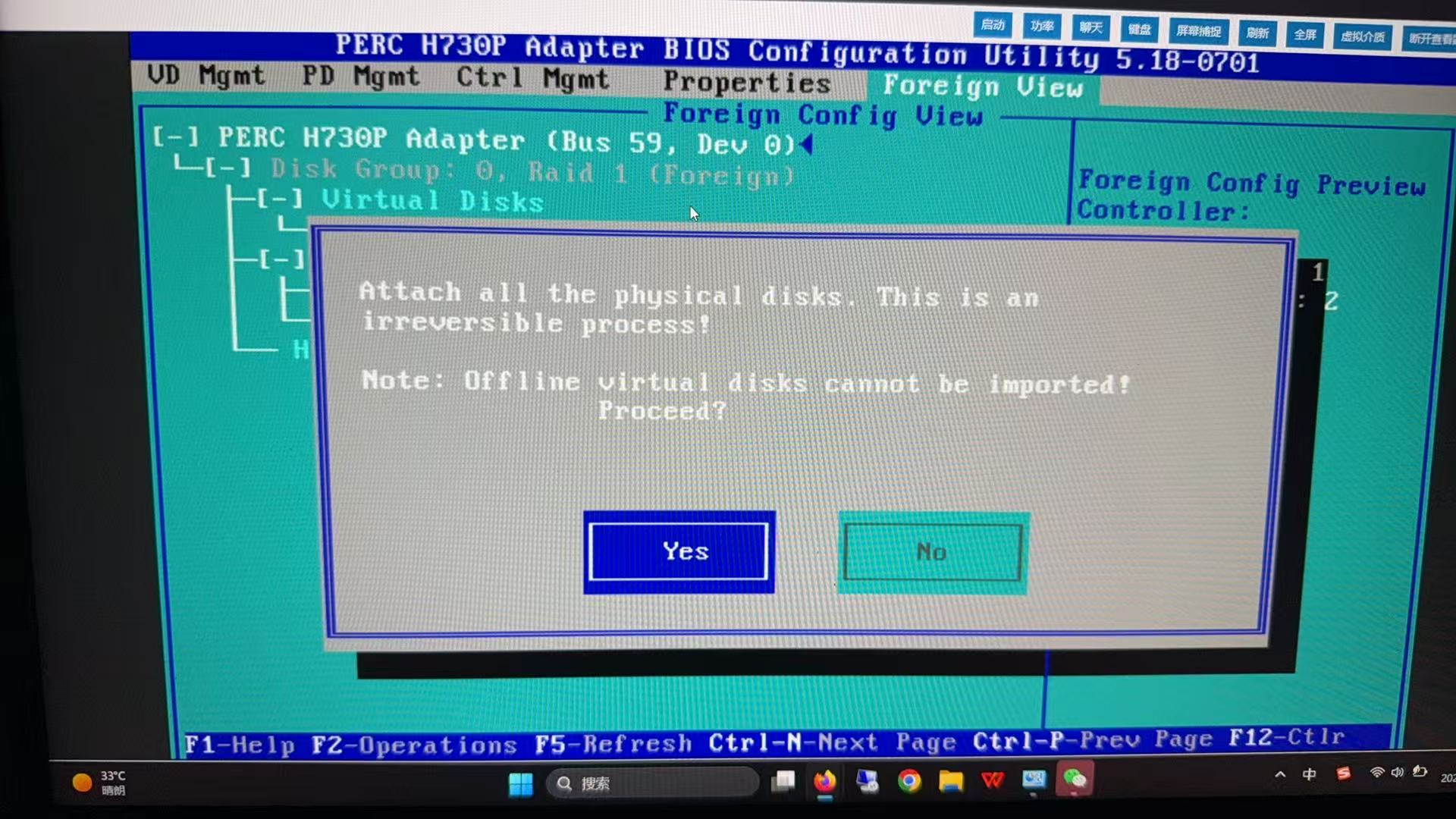
Dell服务器RAID操作:磁盘RAID配置导入
设备厂家:DELL PowerEdge R740
设备序列号:[已脱敏]
更换RAID卡后提示硬盘提示:Foreign
导入硬盘RAID配置:Foreign View——》Foreign config——》Import
如果无法导入,有其他案例更换Raid卡解决。

更换光纤后换标签:拆下原线缆标签,购买标签纸做为补丁,将原标签粘在新线缆上
劳动保护:光纤不能直接看,通过物品反射,或手机摄像头拍摄。
案例分享:服务器内部电子部件的操作规范和引导客户关机放静电的标准话术
1、服务器内部电子部件的操作规范:断电、拔下网线后,按几次服务器开关后再进行部件的更换操作;
2、引导客户关机放静电的标准话术:因为服务器长期运行,一些导电性不强的塑料部件、线缆、卡扣会出现局部静电的累积,对精密的电子部件产生影响。另外机器内部有震动,偶尔出现有这种接触不太好的情况。精密的电子部件出现能容错的微小故障可以自行容错修复,要么就会出现断崖式的性能故障,达到阈值就会带外有报警或直接无法工作。
彻底的方法还是,还是需要关机。插拔里边的设备,顺便可以看看内部部件的情况。
主机配置查询和保修期查询
配置查询专用网址查询
超聚变:最上面、中间的输入序列号,点放大镜
https://support.xfusion.com/server-spareparts/#/zh/home
惠普HP和新华三H3C
https://zhiliao.h3c.com/Theme/details/215925
或HP专用龙海艳提供
https://partsurfer.hpe.com/search.aspx
浪潮
https://support.ieisystem.com/eportal/ui?pageId=2317460&type=4
Dell
直接使用邮件附件中的iDRAC,解压后,再解压,打开Viewer.html
曙光服务小程序需要注册
使用:“曙光服务”小程序——》我的——》售后咨询
其他都需要打电话咨询:烽火、华为、中兴、宝德、IBM、牙木、虹信
配置查询电话查询:
| 序号 | 厂商 | 维护数量 (5月清单) |
电话 | 小程序 |
|---|---|---|---|---|
| 1 | 超聚变 | 3885 | 400 009 8999 | |
| 2 | HP | 3393 | 400 810 0504 | |
| 3 | 新华三 | 745 | 400 810 0504 | 新华三服务 |
| 4 | 浪潮 | 2318 | 400 860 0011 | 浪潮信息专家服务 |
| 5 | DELL | 1558 | 400 881 1858 | |
| 6 | 曙光 | 805 | 400 810 0466 | 中科曙光服务 |
| 7 | 烽火 | 805 | 400 889 0787 | |
| 8 | 华为 | 142 | 400 822 9999 | |
| 9 | 中兴 | 29 | 400 830 1118 | |
| 10 | 宝德 | 22 | 400 887 0872 | |
| 11 | IBM | 6 | ||
| 12 | 牙木 | 2 | ||
| 13 | 虹信 | 1 | 4008550189 | OEM超聚变 |
保修期查询网站查询

李俊华汇总
(双击打开,或右键另存为打开)
故障定位和日志分析
日志解析全部使用记事本打开,注意活学活用。
日志分享我还在逐步完善,根据服务器的带外版本不同,不保证如下提供的方法一定有效,如果遇到疑问可以联系我,逐步完善。
超聚变日志解析:可以挖掘的信息非常多,甚至包含设备的PN码
当前报警1
[内网IP]-2025-06-03-17-31-31.tar(2)\dump_info\AppDump\sensor_alarm\sel.tar——》解压缩——》eo_sel.csv
当前报警2
[内网IP]-2025-05-29-11-29-45\dump_info\AppDump\sensor_alarm\current_event.txt
(这个也要看,可能与1不同)
[内网IP]-2025-06-09-14-29-54.tar\dump_info\LogDump\ maintenance_log
硬盘信息,有nvme固体信息
[内网IP]-2025-06-03-14-29-33.tar.gz\dump_info\AppDump\StorageMgnt\RAlD_Controller_Info.txt
硬盘报错
[内网IP]-2025-06-03-14-29-33\dump_info\LogDump\storage\drivelog\Disk2\SATA_LOG
电源信息
[内网IP]-2025-05-23-16-32-50\dump_info\AppDump\BMC\psu_info
内存信息
[内网IP]-2025-05-23-16-32-50\dump_info\AppDump\CpuMem\mem_info
PCI-E总线上的卡信息及背板信息
dump_info\AppDump\card_manage\card_info
很多信息自己去挖掘
惠普HP的iLO导出的AHS暂时无解,我最近再找方法,试验了3中方法不行,1种方法有些曙光,完成后分享给大家
新华三H3C有的日志很大,要到系统下载 130M左右
具体的报错信息
[内网IP]-2025-06-03-14-27-06\event\具体的起止日期
是Excel表格通过筛选Severity Level——》Minor——》Major
总的设备状态列表
[内网IP]-2025-06-03-14-27-06\static\sensor_info.ini
所有备件的型号和PN码
[内网IP]-2025-09-10-14-56-44\static\ hardware_info.ini
具体的硬盘信息
[内网IP]-2025-06-03-14-27-06\static\LSI_9460_raid_conf[6].txt
(如果没有,可能Raid卡检测不到了。有故障的硬盘不会在这个列表里,要通过排除法,需要结合步骤a进行故障判断)
具体硬盘错误
[内网IP]-2025-06-03-14-27-06\static\smartdata\Front10\first_date_analysis.txt
Reallocated_Sector_Ct (5):已重新分配8个扇区(RAW_VALUE=8),需立即备份数据
Seek_Error_Rate (7):寻道错误率高达222,917,001(RAW_VALUE),远高于阈值45,可能预示磁头或盘片损伤
以这两个主机为例子
210200A00QH193001316
210200A00QH193001294
浪潮日志解析
早期版本
当前错误报警1
解压日志后,在NF5280M5_420936815_10.12.21.45_20250603_142527\bmc\restful目录下再解压bmcOnekeyLog-20250603_142838.tar——》bmcOnekeyLog-20250603_142838\onekeylog——》sel.log
当前错误报警2
\onekeylog\onekeylog\Inspur_NF5466M5_820917786_IDL
早期型号:设备厂家:浪潮 NF8480M4 设备序列号:[已脱敏]
日志BMC\sel_elist.txt有日志,但是需要通过 Unix时间戳 确定时间
2022年生产,2025年过保修的较新主机日志
方法一:
NF5280M6_24A512461_10.17.198.214_20251020_173318\bmc\restful\bmcOnekeyLog-20251020_173551\onekeylog\runningdata\var\ dev_status.log
方法二:
\NF5280M6_24A512461_10.17.198.214_20251020_173318\bmc\restful\bmcOnekeyLog-20251020_173551\onekeylog\log\selelist.csv
硬盘信息:分割符号——》{ "ctrlindex"
NF5280M5_420936815_10.12.21.45_20250603_142527\bmc\restful\raid_controller_pdinfo
内存信息:分割符号——》{ "mem_mod_id":
NF5280M5_420936815_10.12.21.45_20250603_142527\bmc\restful\asset_memory_info
固态硬盘的信息(部分情况下好用)
NF5280M5_420936815_10.12.21.45_20250603_142527\bmc\restful\Asset_device_inventory
新版本浪潮服务器日志:可以读取的信息比较少,主要集中在如下日志中:
dump_21A666019_20260315-1304\onekeylog\log\idl.log
或dump_21A666019_20260315-1304\onekeylog\log\selelist.csv
戴尔日志解析
最简单把邮件附件解压后,目录中的压缩包在解压,打开Viewer.html
曙光服务器日志解析:
I620-G40_XXXX-XXXX-XXXX-XXXX_20251119-1625\bmcblackinfo\bmcloginfo\log\oemlog\ SEL_TRANSLATE.txt
宝德===PR2740TP
双路双节点
双节点===每个节点为独立计算单元物理隔离;
双路===双路指单节点双CPU插槽
HARDWARE_FAULT20250611180932579
设备序列号:[已脱敏]
HARDWARE_FAULT20250611180623312
设备序列号:[已脱敏]
案例分享:服务器riser卡,立卡,扩展转接卡

案例分享:华为交换机CloudEngine 16808使用的的三种板块:SFU、LPU、MPU
MPU -->|控制与管理| SFU;
MPU -->|下发转发表项| LPU;
LPU -->|数据传输| SFU;
SFU -->|数据交换| LPU;
MPU(主控板)是整个系统的“大脑”,负责系统的控制和管理工作,包括路由计算、设备管理和维护、设备监控等,同时作为系统同步单元,提供高精度、高可靠性的同步时钟、时间信号。MPU通过控制通道对SFU进行集中控制和管理,同时将计算好的转发表项下发给LPU。
LPU(线路处理板)也叫接口板,提供各种类型的物理接口,用于与外部设备进行连接,实现数据的接收和发送。LPU将接收到的数据发送给SFU,同时从SFU接收需要转发出去的数据。
SFU(交换网板)主要负责LPU之间的信元交换,实现接口板与接口板、接口板与主控板间的连接,为设备提供高速无阻塞的数据交换通道,使数据能够在各个LPU之间快速且高效地传输。
华三交换机异常重启故障排查方法
<ZJJD01-202-D25_D26-ASW-H5552-01U41_01U41>dis diagnostic-information
Save or display diagnostic information (Y=save, N=display)? [Y/N]:n
===============================================
===============display clock===============
10:52:11.920 UTC+8 Sun 02/01/2026
Time Zone : UTC+8 add 08:00:00
=================================================
===============display version===============
H3C Comware Software, Version 7.1.070, Release 6127
Copyright (c) 2004-2019 New H3C Technologies Co., Ltd. All rights reserved.
H3C S5552S-EI-D uptime is 326 weeks, 4 days, 18 hours, 15 minutes
Last reboot reason : IRF Merge reboot
Boot image: flash:/s5500sei_d-cmw710-boot-r6127.bin
Boot image version: 7.1.070, Release 6127
Compiled Jun 11 2019 11:00:00
System image: flash:/s5500sei_d-cmw710-system-r6127.bin
System image version: 7.1.070, Release 6127
Compiled Jun 11 2019 11:00:00
Feature image(s) list:
flash:/s5500sei_d-cmw710-freeradius-r6127.bin, version: 7.1.070
Compiled Jun 11 2019 11:00:00
Slot 1:
Uptime is 0 weeks,0 days,0 hours,28 minutes
S5552S-EI-D with 1 Processor
BOARD TYPE: S5552S-EI-D
DRAM: 512M bytes
FLASH: 256M bytes
PCB 1 Version: VER.B
Bootrom Version: 130
CPLD 1 Version: 001
Release Version: H3C S5552S-EI-D-6127
Patch Version : None
Reboot Cause : WatchDogReboot
[SubSlot 0] 48GE+4SFP Plus
Slot 2:
Uptime is 326 weeks,2 days,20 hours,37 minutes
S5552S-EI-D with 1 Processor
BOARD TYPE: S5552S-EI-D
DRAM: 512M bytes
FLASH: 256M bytes
PCB 1 Version: VER.B
Bootrom Version: 130
CPLD 1 Version: 001
Release Version: H3C S5552S-EI-D-6127
Patch Version : None
Reboot Cause : IRFMergeReboot
[SubSlot 0] 48GE+4SFP Plus
=================================================
===============display system internal version===============

其次:dis logbuffer reverse
某内部维修群这个群解散了,网络设备查看端口和设备信息:某同事甲 1XX-XXXX-XXXX
工作日外维修打值班电话,联系值班的同事:值班电话 1XX-XXXX-XXXX
采集光模块信息:针对光模块问题或端口闪断的问题
如下为华为、华三:
display sn all
display interface 接口号 transceiver [ verbose ]
display interface 接口号
display logbuffer
查看电源
display device manuinfo
display power
display alarm
查看风扇
display device manuinfo
display fan
sys
display device fan
如下为锐捷: 设备型号:RG-S6510-48VS8CQ
show version
show interface 接口 transceiver
show interface 接口
show interface 接口 transceiver diagnosis
show interface 接口 transceiver manu
show logging reverse
查看电源情况
#查看设备型号、软件/硬件版本、序列号
#检查电源状态
#查看报警信息
#查看硬件信息
show version
show power
show alarm
show inventory
锐捷交换机报错:%DEV_MONITOR-4-POWER_FR: Power unknown in slot 2/2 is different from the system -F mode.
交替重启堆叠主机后故障依旧,备机关机,对调2块电源后正常。需要关机。
如下中兴设备
show serial-number
show interface 接口
show optical-inform details rx-power interface 接口
show optical-inform details tx-power interface 接口
show optical-inform interface 接口
show serial-number
show power
show logging alarm
<FJFZcl-502-HH1001_HH0801-CSW-H12500-21U09> dis tran dia interf HundredGigE2/4/0/5
HundredGigE2/4/0/5 transceiver diagnostic information:
Current diagnostic parameters:
[module] Temp.( Voltage(V)
35 3.27
[channel] Bias(mA) RX power(dBm) TX power(dBm)
1 6.13 -1.80 -1.55
2 6.14 -1.66 -1.58
3 6.13 -1.83 -2.20
4 6.14 -1.77 -2.22
Alarm thresholds:
Temp.( Voltage(V) Bias(mA) RX power(dBm) TX power(dBm)
High 80 3.60 12.00 5.40 5.40
Low -10 3.00 0.00 -14.00 -12.10
<FJFZcl-502-HH1001_HH0801-CSW-H12500-21U09> dis tran interf HundredGigE2/4/0/5
HundredGigE2/4/0/5 transceiver information:
Transceiver Type : 100G_BASE_SR4_QSFP28
Wavelength(nm) : 850
Transfer Distance(m) : 70(OM3),100(OM4)
Digital Diagnostic Monitoring : YES
Vendor Name : H3C
Ordering Name : QSFP-100G-SR4-MM850
<FJFZcl-502-HH1001_HH0801-CSW-H12500-21U09>dis logbuffer reverse | include HundredGigE2/4/0/5
%Jun 9 09:48:09:127 2025 FJFZcl-502-HH1001_HH0801-CSW-H12500-21U09 SHELL/6/SHELL_CMD: -Line=vty0-IPAddr=[内网IP]-User=COC_operator; Command is dis logbuffer reverse | include HundredGigE2/4/0/5
%Jun 9 09:47:55:048 2025 FJFZcl-502-HH1001_HH0801-CSW-H12500-21U09 SHELL/4/SHELL_CMD_MATCHFAIL: -User=COC_operator-IPAddr=[内网IP]; Command dis log res | in HundredGigE2/4/0/5 in view shell failed to be matched.
%Jun 9 09:47:37:680 2025 FJFZcl-502-HH1001_HH0801-CSW-H12500-21U09 SHELL/6/SHELL_CMD: -Line=vty0-IPAddr=[内网IP]-User=COC_operator; Command is dis tran interf HundredGigE2/4/0/5
%Jun 9 09:47:32:470 2025 FJFZcl-502-HH1001_HH0801-CSW-H12500-21U09 SHELL/6/SHELL_CMD: -Line=vty0-IPAddr=[内网IP]-User=COC_operator; Command is dis tran dia interf HundredGigE2/4/0/5
%Jun 9 09:47:22:849 2025 FJFZcl-502-HH1001_HH0801-CSW-H12500-21U09 SHELL/6/SHELL_CMD: -Line=vty0-IPAddr=[内网IP]-User=COC_operator; Command is dis interf HundredGigE2/4/0/5
%Jun 9 09:26:29:899 2025 FJFZcl-502-HH1001_HH0801-CSW-H12500-21U09 SHELL/6/SHELL_CMD: -Line=vty2-IPAddr=[内网IP]-User=COC_operator; Command is display interface HundredGigE2/4/0/5
案例分享:关于RAID0在某云厂商系统里使用的两种情况分享:
RAID0性能最优,空间利用率最高,但没有数据冗余,企业环境基本不使用。但在某云厂商系统里发现了两种应用场景:
应用场景一:
某些省份发现为满足 业务前置机快速转发 的需求,无数据安全考虑不要求保留日志,所以用RAID0追求性能最大化。
针对这种情况,又分两种情况:
1.硬盘告警灯亮,RAID0没有崩,数据还在可以正常访问:
2.硬盘故障已经无法读取,RAID0已经崩了:用户已经无法读取数据了;
所以我们更换硬盘的时候,先跟客户确认是否为RAID0,数据丢失能否接受,数据要不要恢复,不要贸然更换硬盘。
应用场景二:
现在河南和江西已经有明确的反馈,RAID卡里配单硬盘RAID0,操作系统里通过软件配置的软RAID。
主机是RAID卡配置单硬盘RAID0,Linux下通过软RAID块状存储(或称多副本)做的软RAID,更换硬盘需要在系统里确认物理盘和系统存储卷之间的对应关系。而这个对应关系,不是一对一的,是交错对应的。需要Linux系统工程师确定这种对应关系,有的时候Linux系统里还安装了阵列卡工具的rpm包。
具体的实现方法与Ceph或mdadm相关,涉及的面就非常广泛了,有兴趣的话可以自行学习和研究。
针对如上这两中应用场景我们要做的事情:
针对应用场景一:确认数据备份过、现有硬盘里数据不要了、不用恢复后,在RAID卡里配置RAID0
针对应用场景二:由某云厂商系统工程师确定故障硬盘卸载后,更换硬盘,在RAID卡配置单盘RAID0
确认是否为RAID0有以下几种方法:
用户报修的故障维修单备注里会写RAID10等,使用排除法;
联系用户的时候,跟业务接口人确认,或维修群换件时确认,让客户点亮硬盘更换;
BMC带外管理里查看;
如果用户无法确认,可能根据硬盘容量估算(磁盘单个容量*磁盘个数),但需要用户确认的微信聊天内容留痕;
通过lsblk命令查看,如果出现sda、sdb……sdn,等多个设备与物理硬盘数量基本相同就可以确定是单盘RAID0;
如下部分内容来自李俊华的分享
【问题描述】昆明2b2 资源池主机: cc-ynkm2b2-arm-ceph-1503-4 管理IP:[内网IP] 设备序列号:[已脱敏] enp2s0f0、enp2s0f1网卡down,全部光模块更换
【解决方案】2025-05-22-22:00 无需停服下电关机,厂商热更换硬件
【影响范围】
【是否sata池】维修前确认是否为sata盘(若是要安排在00点后维修)
特殊情况说明:热更换Raid1 系统硬盘如果OS同事也确认可以操作,则执行 ,如果反馈不行则按正常的关机停服流程维修
具体操作流程:
1.ceph --id cephfs -s ,检查ceph集群状态,当集群状态为health时,设置noout的标志位(执行ceph osd set noout,ceph osd set noup,ceph osd set noin)(平台:胡gn)【同资源池多节点维修时,每维修完一台,需检查ceph集群状态再次为health后,再维修下一台,若维修后服务器无法启动,立刻停止维修并联系ceph研发处理】
2.厂家工程师热更换硬件,并清除带外告警异常日志(厂家:虹信-徐志高)
3.开机后,在其他存储节点长ping -s 8192 -c 100 -q -i 0.5 x.x.x.x维修节点存内网、存外网100秒,确认网络正常,然后严格按顺序取消标志位
:ceph osd unset noup , ceph osd unset noin,ceph osd tree 检查都起来后再ceph osd unset noout(平台:胡gn)
4.检查硬盘健康情况smartctl -a /dev/xxx盘符,并读写和速度是否正常 (平台:胡gn)
热更换系统盘的,检查新换的磁盘通电时间和检查磁盘有无坏道
系统盘是两块盘组成的,00表示第一块,01表示第二块
sudo smartctl -a -d cciss,00 /dev/sda
sudo smartctl -a -d cciss,01 /dev/sda
sudo smartctl -a -d megaraid,01 /dev/sda
sudo smartctl -a -d megaraid,02 /dev/sda
5.对维修节点用uname -r查看内核版本,并检查相邻管理IP节点内核版本是否一致:(平台:胡gn)
6.厂家确认维修完成,我们平台运维相关检查正常,厂家可离场;通知业务运维设置故障状态,在表里【业务验证是否正常】填写“待验证”即可,业务同事抽空去检查业务(业务:王zp)
7.人工检查是否存在up但out的osd,若有则执行 ceph osd in osd.${id},手动将osd in入集群,判断:ceph osd tree | grep <维修主机名> -A 24 查看,两个1.00才是in,出现了一个1.00就需要手动加入集群(平台:胡gn)
在Linux下实现软RAID通常会使用mdadm软件,以下是其相关介绍及具体方案:
mdadm软件
- 简介:mdadm是Linux下用于管理软件RAID设备的工具,它支持多种RAID级别,如RAID0、RAID1、RAID5、RAID6和RAID10等。
具体方案
以创建RAID5为例,步骤如下:
1. 安装mdadm:在大多数Linux发行版中,可以使用包管理工具来安装mdadm,如在CentOS中,执行 yum install mdadm 命令。
2. 查看磁盘设备:使用 fdisk -l 或 lsblk 命令查看系统中的磁盘设备,确定要用于创建RAID的磁盘。
3. 创建RAID设备:假设要使用 /dev/sdb 、 /dev/sdc 和 /dev/sdd 这三块磁盘创建RAID5设备 /dev/md0 ,可以执行命令 mdadm -C /dev/md0 -l 5 -n 3 /dev/sdb /dev/sdc /dev/sdd 。其中, -C 表示创建新的RAID设备, -l 指定RAID级别, -n 指定参与RAID的磁盘数量。
4. 查看RAID状态:使用 mdadm -D /dev/md0 命令可以查看RAID设备的详细信息和状态。
5. 格式化RAID设备:创建好RAID设备后,需要对其进行格式化,例如格式化为ext4文件系统,执行 mkfs.ext4 /dev/md0 命令。
6. 挂载RAID设备:在 /etc/fstab 文件中添加相应的挂载条目,以便系统在启动时自动挂载RAID设备,如添加 /dev/md0 /mnt/raid5 ext4 defaults 0 0 ,然后执行 mount -a 命令使挂载生效。
这只是一个基本的软RAID创建方案,实际应用中可根据需求调整RAID级别、磁盘数量等参数。同时,还可以设置热备盘、监控RAID状态等以提高系统的可靠性和可管理性。
案例分享:Linux操作系统内磁盘告警,带外无显示告警:
设备序列号:[已脱敏]
厂家来的信息:设备厂家 曙光 I620-G30
原厂硬盘 480G固态*2 1.8T,SAS*12
报障现象:系统内磁盘告警,带外不显示告警,请加急维修
实际情况:系统内有两块RAID卡,其中一块检查不到了,12块硬盘组成的RAID10检测不到了,BMC上没显示,没有报警。
Raid卡型号:3316 - 16i 4GB SAS12G RAID卡
确定的原因:拆开机箱,发现RAID卡散热片掉了,RAID卡背面颜色很深,接近烤糊了。重新安装散热片后竟然可以再次使用,持续观察,查看之后是否有类似的维修保修记录



英伟达Gpu的命令
nvidia-smi -a
lspci -nnvv
lspci -vt
nvidia-bug-report.sh
疑难案例分享:电源一路PSU在BMC经常报警
超聚变RH2288H V5 7台电源批量问题找到原因了,
疑难案例分享:
现象:电源一路PSU在BMC经常报警,快的时候1分钟内故障/异常出现7次反复。通过和某云厂商报障人确定,查询硬件配置信息,发现之前维修过,换的电源同为550W,但品牌不一样。后来咨询超聚变客服,确认了是会出现这总问题,原因:主板直接接PSU电源,没有电源背板。
这种情况,请大家注意一下,一句话总结:超聚变RH2288H V5 主板没有电源背板,更换电源需要同品牌同型号的电源。需要相同型号PN码。
可能的原因和测试方法:
1、混插了不同PN码的电源,同样550W的电源也不行——》测试方法:关机断电,拆下PSU电源,核对两个PSU电源PN码;
2、检查电源线和PDU插排——》测试方法:电源线对调,服务器PSU1接由A路接B路供电
3、主板直接接PSU电源,没有电源背板——》需要对调电源测试——》必要时更换主板或电源
RH2288H V5
2102311TYBN0K7007153、2102311TYBN0K7006732、2102311TYBN0K7006828、2102311TYBN0K7006811、2102311TYB6TK8000521、2102311TYBN0K7007155
换电源
2102312BJRN0K8000166
RH2288H V5 PN:02131255:550W
BMC的固件没有类似问题的反馈。
工程师现场感受体感温度稍高,实际上是根据进风Inlet的温度调风扇转速的百分比。调高风扇转速(有效性待验证):

这个项目并不是给某云厂商机房全面的解决问题的,只是让他们符合某云厂商和集团公司相关的考核标准,同时满足业务接口人的满意度!
有大局观念:公司和项目是大树的根部,员工和工程师枝叶,树根有营养枝叶才能繁茂!
